Размер паркета: толщина, ширина, длина, описание стандартов
толщина, ширина, длина, описание стандартов
От таких простых, но важных показателей, как толщина паркетной доски или паркета, а также длина и ширина, зависит качество напольного покрытия, срок его службы, внешний вид. Существуют определенные стандарты, согласно которым производители выпускают продукцию. Четкое ориентирование в параметрах паркета и паркетной доски с пониманием их влияния на эксплуатационные характеристики поможет сделать правильный выбор.
Паркет — про общие стандарты
Натуральный деревянный паркет — это всегда практично, надежно и респектабельно. Покрытие на основе паркета может состоять из паркетных досок и штучных клепок. Небольшие со строгой геометрией доски, натертые до блеска и уложенные в определенном порядке, позволяют создавать в помещении особую атмосферу тепла и уюта.
Выбирая материал, стоит помнить о том, что роль играет все, начиная от типа материала и заканчивая геометрией, размерами (толщина паркета, ширина и длина), способом сушки.
Важный момент — степень влажности материала. Речь идет не только о степени просушки, но и о способе. Лучший — паркет, просушенный вакуумным методом, а вот материал, полученный в результате воздушно-парового способа не самое правильное решение, так же, как и высушенные в природных условиях комплектующие.
Только высушенный в вакууме паркет при температуре в диапазоне от 52 до 70 градусов будет иметь идеальную поверхность без трещин, не подвержен влиянию влаги.
Что нужно знать о размерах паркета
Чтобы покрытие прослужило много лет, толщина паркета для пола должна быть не менее 15-16 мм. Если плашки будут тоньше, то срок их службы сократится как минимум в два раза. Тогда как более толстый паркет потеряет в отношении показателей эластичности.
Не менее важный нюанс — соотношение между шириной и длиной плашек. Необходимо, чтобы оно было цельно-кратным, так как основа большинства рисунков — квадрат. Пропорциональность величин упростит процесс монтажа с намеченным узором.
Согласно ГОСТу производители получают стандарт для показателя шероховатости поверхности. Оптимальный показатель шероховатости — 125 мм. От геометрической точности изготовления клепок будет зависеть необходимость проведения шлифовальных работ на ту или иную толщину.
Виды паркета и параметры — как отличаются
Нужно понимать, что стандартные размеры паркета во многом определяются типом материала. Выделяют следующие его виды:
- штучный;
- щитовой;
- паркетная доска;
- наборной;
- массивная доска;
- пронто-паркет.
Штучные планки из дерева стандартно реализуются с толщиной от 40 до 70 мм, длиной от 200 до 500 мм и шириной от 14 до 22 мм. Для удобства крепления грани плашек оснащены шипами и пазами.
С тыльной стороны планки оснащены прорезями, обеспечивающими снятие внутренних напряжений на древесных волокнах, что позволяет исключить коробление покрытия. В целом такой паркет требует особого подхода к монтажу из-за трудоемкости работ.
Щитовой паркет
Щитовой паркет представляет собой многослойную плашку на основе хвойной подложки и планок из ценных пород дерева. Стандартно планки имеют показатели: 400×400 мм или 800×800 мм при ширине от 20 до 40 мм. Рабочий слой плашек — от 5 до 15 мм.
Массивные плашки с лаковым или масляным покрытием — это чаще стандартная ширина доски от 120 до 200 мм, толщина от 18 до 22 мм, длина от 2000 до 2500 мм. Так же, как и штучный паркет, доски имеют пазы и шипы для крепления. По сравнению с многослойным щитовым паркетом, массивная доска более практична и надежна в эксплуатации.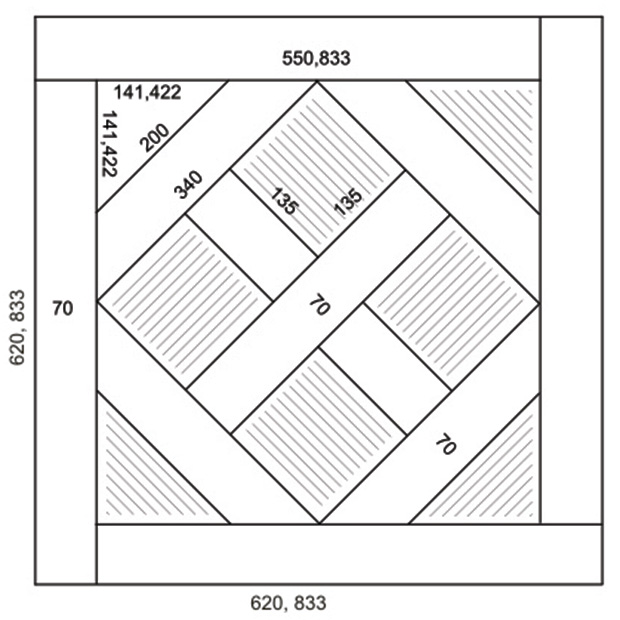
Наборной паркет представляет собой одинаковой ширины плашки из ценных пород дерева, подходящие для формирования узоров. Лицевая часть планок зафиксирована на основе из специальной бумаги, перед монтажом которою можно снять, тыльная имеет подложку.
И, наконец, не так часто используемый из-за недавнего появления на рынке пронто-паркет — это ничто иное, как скрепленные из нескольких прессованных слоев с перекрестной фиксацией доски. Конструкция фиксируется на замочных элементах шпунтового соединения. Толщина квадрата пронто-паркета составляет от 10 до 14 мм.
Для лицевого слоя используются ценные породы дерева. Его толщина не менее 4 мм. Такой материал реализуется с лаковым покрытием и без него. Он отлично справляется с перепадами температуры, влажности, достаточно практичный и долговечный. Монтировать покрытие просто и быстро.
По цветам и оттенкам паркет размеры которого определяют в зависимости от особенностей и назначения помещения делят на светлый, желтый, коричневый, красный, розовый и темный.
О параметрах паркетной доски — что учитывать
Паркетная доска — более доступный аналог натурального паркета. Устройство качественного пола на основании этого материла потребует определенного анализа его параметров. Следует понимать, что паркетная доска размеры имеет настолько разные, насколько производители считают нужным разнообразить ассортимент продукции. И пусть отличия между основными параметрами небольшие, они есть и их нужно учитывать.
Итак, геометрия материала подразумевает, что длина паркетной доски должна колебаться в диапазоне от 1,8 до 2,5 см, при толщине от 0,7 до 2,5 см и ширине от 13 до 20 см. Выбирать плашки подходящих размеров нужно из учета конструкции пола, а также требований к долговечности покрытия.
На срок службы и практичность паркетного пола в наибольшей степени влияет толщина доски. Исходя из этого, выделяют следующие ее варианты:
- 0,7 см;
- 1 см;
- 1,3-1,5 см;
- 2 см;
- 2,2 см;
- 2,5 см.


Доска с толщиной 0,7 см наиболее тонкая, с лицевым слоем из шпона, не предназначенная для циклевки, подходит для помещений, где нет возможности увеличивать высоту пола. Доска с толщиной в 1 см имеет небольшой рабочий слой, поэтому может срезаться в процессе отделки до 2,5 мм.
Доски с толщиной от 1,3 до 1,5 см — лучший вариант для монтажа теплого пола. Двухсантиметровые плашки с рабочим слоем в 6 мм отличаются особенной прочностью, подходят для монтажа пола в помещениях общественного назначения. Наиболее значимая — толщина 20 мм и выше.
Доска с такими параметрами обладает самым высоким уровнем сопротивляемости нагрузкам, идеально подходит для устройства пола в аэропортах, офисах, торговых центрах.
В заключение о том, насколько удобна длинная паркетная доска и почему ее следует предпочесть короткой. Длина плашки напрямую связана с энергией шага. Чем длиннее доска, тем тише шаг и меньше вибрация. Кроме того, по истечению определённого времени такая доска будет меньше скрипеть. Доска с длиной до 1,8 м, а особенно трехполосная не только выглядит не эстетично, но и не практична. В ходе использования возможно расхождение швов и общая деформация покрытия.
Доска с длиной до 1,8 м, а особенно трехполосная не только выглядит не эстетично, но и не практична. В ходе использования возможно расхождение швов и общая деформация покрытия.
Штучный паркет — небольшие планки из массива ценных пород дерева
Штучный паркет — это деревянное напольное покрытие, состоящие из цельных планок с шипами и пазами для соединения в полотно. Планки штучного паркета делают из массива дуба, ясеня и других пород ценной древесины.
Отличия штучного паркета от массивной доски
Грань между массивной доской и штучным паркетом размыта. Поскольку современные производители широко варьируют размеры массивной доски и штучного паркета, нет никаких чётких требований, где заканчивается один вид паркета и начинается другой.
И всё же планки штучного паркета обычно у́же и короче, чем доски массива, и стоят дешевле, т. к. для их изготовления не нужна большая площадь допустимой по качеству древесины. А ещё чаще всего в упаковке штучного паркета планки все одинаковые по размеру, а у массивной доски — разной длины.
к. для их изготовления не нужна большая площадь допустимой по качеству древесины. А ещё чаще всего в упаковке штучного паркета планки все одинаковые по размеру, а у массивной доски — разной длины.
Есть небольшая разница и в укладке: массивная доска обычно укладывается вдоль комнаты с разбросом стыков, реже — поперёк или по диагонали. Штучный паркет можно укладывать разными рисунками. Иногда продают штучный паркет, специально нарезанный для укладки французской ёлкой, — со срезами торцевых сторон.
Конструкция у штучного паркета и массивной доски одинаковая.
Без уточнения размеров непонятно, что изображено на картинке
Размеры
Традиционные размеры планки штучного паркета — 250 x 50 x 15 мм. Действующий ГОСТ «Паркет штучный» допускает выпуск планок шириной от 30 до 90 мм с шагом в 5 мм и длиной от 150 до 500 мм с шагом в 50 мм.
Каждый производитель предлагает свои размеры штучного паркета, поэтому перед покупкой обязательно проверьте размерность планок и однородность длин. Бывает, что в упаковке предлагаются планки разной длины. Такой паркет подойдёт только для укладки вразбежку.
Бывает, что в упаковке предлагаются планки разной длины. Такой паркет подойдёт только для укладки вразбежку.
Для укладки вразбежку подойдут планки разной длины,
а, например, для ёлочки — только одинаковые
Породы дерева
На выборах президента среди пород дерева для изготовления штучного паркета с огромным отрывом лидирует дуб. Следом за ним идёт ясень, а дальше около 1-3 процентов голосов — у всех остальных пород, включая экзотические, вроде мербау, палисандра и тика.
У дуба, ясеня и бука прочная древесина с плавными линиями волокон. Такой паркет надёжный и стабильный. Он имеет сдержанный благородный оттенок.
Отличными визуальными и техническими характеристиками обладает паркет из американского ореха. Его текстура более крупная, а оттенки теплее, чем у дуба. Орех твёрже дуба: 5,0 против 3,8 по Бринеллю.
Штучный паркет из американского ореха, уложенный ёлочкой, очень красив
Обработка
Раньше штучный паркет выпускался только «в чистом виде». После установки пол шлифовали, а затем покрывали лаком. Такой паркет и сейчас можно приобрести, он стоит дешевле, чем планки с отделкой и под лаком.
После установки пол шлифовали, а затем покрывали лаком. Такой паркет и сейчас можно приобрести, он стоит дешевле, чем планки с отделкой и под лаком.
Последние в заводских условиях шлифуются, тонируются или брашируются и покрываются лаком или маслом. Такой паркет полностью готов к монтажу, после которого нужно лишь дождаться высыхания клея — и ваш пол готов.
Штучный паркет Дуб Натур от Романовского паркета без обработки,
стоимость 1 кв. метра — 1042 рубля
Установка
Установка штучного паркета по технологии сходна с укладкой массивной доски.
На подготовленное основание сначала приклеивают или привинчивают фанерные листы, распиленные на квадраты или прямоугольники.
Затем на специальный паркетный клей приклеивают сами паркетные планки, выкладывая их в нужном ритме и последовательности.
Работа по установке штучного паркета требует гораздо больше умений и опыта, чем при установке паркетной доски. А поскольку паркет укладывают один раз на долгие годы, специалисты советуют доверять эту работу профессиональным пакетчикам.
Укладка штучного паркета ёлочкой
Раскладка
Штучный паркет хорош тем, что его можно укладывать разными способами, создавая нужный рисунок паркета на полу.
Палуба
Это когда планки укладываются рядами со сдвигом стыков. В зависимости от сдвига рисунок получается с хаотичным или размеренным ритмом.
В небольших помещениях эффектно выглядит укладка палубой по диагонали.
Такой паркет зрительно вытягивает помещение.
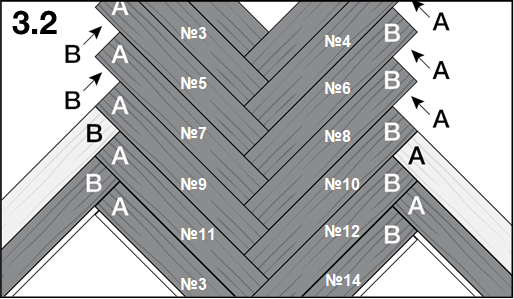
Английская ёлка
Этот рисунок собирается из обычных прямоугольных планок, уложенных под углом 90 градусов друг к другу. При этом у «ёлки» может быть как по одной, так и по две планки в каждом стыке.
Дубовый паркет, уложенный одинарной английской ёлкой
Французская ёлка
Это более современный и стильный рисунок, который делается из запиленных под углом 45 градусов планок штучного паркета. Если покупаете штучный паркет, полностью готовый для укладки французской ёлкой, в заводской упаковке находится равное количество правых и левых планок.
Штучный паркет из дуба с тонировкой, укладка — французская ёлка
Есть и другие способы укладки штучного паркета: квадраты, плетёнка, ромбы. Но они применяются гораздо реже.
Штучный паркет и паркетная доска
Штучный паркет, профессионально уложенный, прогрунтованный и покрытый лаком, выглядит благородно и красиво. Более мелкий, чем у массивной доски, рисунок пола, подходит для небольших помещений, то есть для большинства современных квартир.
Но если добавить к сравнительно невысокой стоимости штучного паркета стоимость услуг паркетчиков, цена окажется примерно такой же, как цена хорошей массивной доски.
Гораздо доступнее — трёхполосная паркетная доска. После установки она выглядит как штучный паркет, уложенный вразбежку, не требует шлифования и покрытия лаком, а установить её почти так же просто, как ламинат.
Трёхполосная доска выглядит как штучный паркет, уложенный вразбежку.
Паркетная доска Ясень Сайма от Барлинек
Запомнить
Штучный паркет у́же и короче, чем массивная доска, но сделан из цельного массива.
Планки стыкуются с помощью шипов и пазов.
На рынке всё ещё есть предложения классического штучного паркета из одинаковых по длине дубовых или ясеневых планок, не покрытых лаком.
Есть и штучный паркет с финишной отделкой, иногда даже заботливо нарезанный под укладку французской ёлкой.
Установку штучного паркета лучше доверить профессионалам.
Если не хватает денег на штучный паркет, можно положить в комнате трёхполосную паркетную доску. Она выглядит как штучный паркет вразбежку, а с установкой можно справиться самостоятельно.
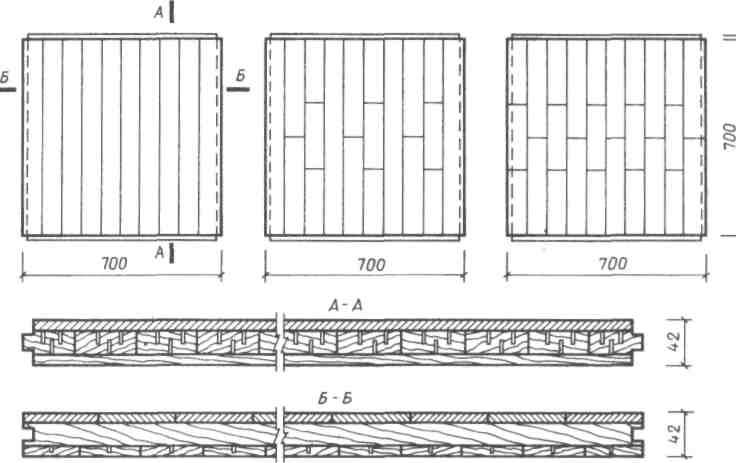
Толщина паркетной доски с подложкой и без – размеры доски
Параметры паркетной доски имеют решающее значение для выбора. Обусловлено это последующей эксплуатацией в различных условиях. Чтобы правильно подобрать это напольное покрытие исходя из нюансов помещения и проходной активности, важно знать размер паркетной доски, инертной к динамическим нагрузкам. Подробности здесь
Параметры паркетной доски имеют решающее значение для выбора. Обусловлено это последующей эксплуатацией в различных условиях. Чтобы правильно подобрать это напольное покрытие исходя из нюансов помещения и проходной активности, важно знать размер паркетной доски, инертной к динамическим нагрузкам.
Обусловлено это последующей эксплуатацией в различных условиях. Чтобы правильно подобрать это напольное покрытие исходя из нюансов помещения и проходной активности, важно знать размер паркетной доски, инертной к динамическим нагрузкам.
Содержание:
Селекция паркета
Виды паркетных досок
Заключение
Селекция паркета
Внешний вид лицевого слоя паркетной доски зависит от распила древесины – селекции. Классификация по тону, рисунку, наличию природных дефектов, помогает приобрести покрытие, максимально подчеркивающее стиль дома. Варианты распила, следующие:
1. Селект. Распил радиальный, проходящий по годовым кольцам. Цвет ровный без резких переходов и контрастов.
2. Натур. Тангенциальный распил – по касательной к кольцам древесины. Природный рисунок часто содержит небольшие вкрапления сучков и других природных дефектов. Возможны вариации с тоном.
3. Рустик. Смешение цветов ярко выражено. Распил смешанный. Присутствуют сучки, тона переходят один в другой.
Распил смешанный. Присутствуют сучки, тона переходят один в другой.
Соответственна и цена. Селект считается элитным типом. Его устраивают в гостиных, кабинетах, залах. Натур – спокойный, благородный. Подходит для спален и проходных комнат. Рустик – бюджетный вариант паркетной доски, не теряющий собственной прелести – с ним хорошо сочетается стиль эко, кантри или деревенский.
Виды паркетных досок
По стандартам, введенным в действие с 1986 года, всю паркетную доску делили на три вида – ПД1, ПД2, ПД3. Аббревиатура обозначала технику выполнения слоев материала – перпендикулярно или продольно оси. Сегодня нормы другие, по количеству продольных плашек:
• Однополосная доска. Декоративный слой выполнен из цельной древесины или шпона. Природный рисунок проступает отчетливо либо виден только однородный тон. Паркетная площадь выглядит единым целым. Хорошо смотрится под любым покрытием – маслом, лаком, воском.
• Двухполосная доска. На одном покрытии полосы бывают длинными или укороченными. Первые используются для длинных и больших помещений. Вторые – соответственно в компактных. Чтобы подчеркнуть красоту паркета используют прозрачный лак.
Первые используются для длинных и больших помещений. Вторые – соответственно в компактных. Чтобы подчеркнуть красоту паркета используют прозрачный лак.
В соответствии с рекомендациями и собственными комнатами правильно выбрать вид паркетной доски – просто.
Толщина паркета для пола
Параметры имеют особое значение для долговечности и ремонтопригодности паркета. Иногда, значительная толщина паркетной доски для пола неприемлема, если высота основания значительна и вкупе с дверными проемами создает проблемы, как эстетические, так и функциональные. Значение варьируется от 0,07 см до 2,6 см.
• Тонкие паркетные доски, чей лицевой слой – это шпон благородных пород, быстро изнашиваются, в зависимости от проходной активности помещения. Циклевать их тоже не получится.
Циклевать их тоже не получится.
• Для укладки в домах, квартирах, производственных помещениях – офисах, кабинетах, приобретается доска толщиной до 0,15 см. Ее верхний слой составляет 4 мм. Циклевка предполагается до 3 раз.
• Комнаты, испытывающие нагрузку и постоянную активность, нуждаются во внушительных параметрах. Там подойдет толщина паркета в 20 мм с верхним слоем в 6 мм. Подлежит ремонту до 5 раз.
Обязательно учитывается толщина паркетной доски с подложкой. Также выбор доски зависит от способа укладки. Например, укладка на лаги, где паркет будет испытывать напряжение от простой ходьбы, требует параметра в 22 мм и выше.
Длина
Диапазон параметра – 1,2–2,5 м. Выбирая доски большей длины, владелец помещения приобретает выгоду в минимизации отходов и обрезов. Такая единица, если учесть еще и максимальную толщину имеет лучшее сопротивление перепадам температуры, влажности. Обладает простотой и скоростью укладки. Однако, если задуман определенный стиль, паркет теряет эстетику, более походя на обычные половые доски. Средние значения – это оптимальный выбор для квартиры и дома.
Ширина
Диапазон – от 13 до 20 см. Как и длина, максимальный параметр позволит быстрее закончить отделку. Покрытие хорошо выдерживает условия проходных помещений, прихожих с перепадами температур, влажностью и ежедневной уборкой. Однако, есть нюансы: широкая доска зрительно уменьшит комнату. Ее позволительно стелить в габаритных гостиных, длинных коридорах, при высоких потолках.
Заключение
Выбирая определенные доски для паркета, следует ориентироваться не только на внешний вид декоративного слоя, но и его толщину. В будущем это позволит отремонтировать покрытие несколько раз. Размер паркетной доски «стандарт» имеет значение для экономической цели – меньше брака, быстрота укладки. Но если задуман определенный стиль, то придется пересмотреть приоритеты.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Производители паркета из видов дерева, размеры и укладка.
Рынок строительных материалов сегодня широк и разнообразен, но особое место до сих пор занимает паркет. Отличительной чертой доброкачественного паркета является его прочность на износ. Производители готовы предложить различные типы паркета, которые отличаются между собой многими параметрами.
Породы дерева для изготовления паркета:
1. Дубовый паркет отличается оптимальным соотношением цены и качества. Данный вид паркета придает помещению благородный вид, который с годами приобретает добротность и изысканность, благодаря тому, что сам паркет из дуба высокопрочен, устойчив к изменению влажности и с годами темнее;
2. Паркет из ясеня, ни с каким иным не спутаешь, благодаря наличию особенной желтизны и полосчатым рисунком среза. Отличается высокой прочностью в совокупности с пластичностью дерева, что дает возможным использовать паркет из ясеня в спортивных залах и многолюдных офисах;
3. Буковый паркет столь же прочен, как и дубовый, но отличается высокой чувствительностью к изменению влажности. Его неповторимый ровный структурный фон светлого или рыжеватого оттенка прекрасно вживается в любой интерьер, но используется чаще всего для отделки стен;
Его неповторимый ровный структурный фон светлого или рыжеватого оттенка прекрасно вживается в любой интерьер, но используется чаще всего для отделки стен;
4. Паркет из клена обладает особенностью с годами из молочно белого преображаться в неотразимый медовый оттенок;
5. Ореховый паркет отличается рельефностью и особенно отчетливым структурным рисунком. Помимо этого орех обладает высокой степенью твердости, но при этом легко поддается обработке и не растрескивается с течением лет даже в сухом помещении;
1. Штучный паркет представлен брусками, имеющими специальные пазы и гребни, что определяет прочное соединение их между собой. Обычные размеры стандартного бруска паркета длина 150 — 600 мм, ширина 30 — 100 мм, толщина 16 мм. Отличаются в основном по рисунку, который бывает следующих разновидностей селект (однородный, но мелкий), натур, контраст, гест, классик, универсал или антик. Но любой паркетный брусок должен быть без трещин, сколов и иных дефектов;
2. Наборный паркет представлен квадратными щитками стандартных размеров 400 х 400 или 600 х 600 с толщиной от 8 до 12 мм. Эти щитки лицевой стороной оклеиваются защитной бумагой, которая после укладки аккуратно снимается.
Наборный паркет представлен квадратными щитками стандартных размеров 400 х 400 или 600 х 600 с толщиной от 8 до 12 мм. Эти щитки лицевой стороной оклеиваются защитной бумагой, которая после укладки аккуратно снимается.
3. Паркетная доска имеет стандартные размеры: длина 2000 — 2700 мм, ширина 130 — 210 мм, толщина 7 — 25 мм и производится из нескольких слоев дерева: основание – пиломатериал низкого сорта, а лицевая сторона толщиной в 3 — 4 мм из твердых пород дерева. Еще на конвейере такой паркет покрывается защитным лаком, то есть после укладки циклевание не производиться.
4. Щитовой паркет многослойный аналог наборного паркета, представленный основанием из древесно волокнистой плиты или доски, далее идет наклеивание мелких планок твердых пород дерева. Стандартные размеры либо 400 х 400, либо 800 х 800 с толщиной от 15 до 30 мм. После укладки циклевание не требуется, потому как имеется заводское нанесение лака.
5. Пронто-паркет многослойный паркет из натурального дерева, имеющий готовое лаковое покрытие заводского происхождения. Подвергается длительной и тщательной обработке, что делает его дорогим, но отличается высокой прочностью и износостойкостью, в отличии от того же линолеума.
На качество паркета максимальное влияние оказывает процесс сушки. Где важен и конечный показатель влажности готового паркета, и способ производственной сушки. Лучшей сушкой сегодня считается вакуумная, самой не качественной в данном отношении является обычная воздушная сушка.
Следующим определяющим параметром качественного и износостойкого паркета является размер и точность/подогнанность отдельных его элементов. Максимальной прочностью обладает паркет «сложенный» из элементов (плашек) с базовой толщиной в 15 — 16 мм, меньшие параметры приводят к быстрому стиранию паркета, а более толстые делают его излишне упругим и способным впитывать влагу, что приводит к скорейшей деформации. Но сегодня производят паркет с толщиной элементов в 22 мм, который необходим для помещений со значительными нагрузками на пол. Ширина и длина элементов скорее влияют на эстетические качества паркета, чем на его прочность.
Но сегодня производят паркет с толщиной элементов в 22 мм, который необходим для помещений со значительными нагрузками на пол. Ширина и длина элементов скорее влияют на эстетические качества паркета, чем на его прочность.
Качественные паркетные элементы можно определить аккуратным проглаживанием рукой сложенных вместе 4 — 5 штук, либо щекой, но только после предварительного тест-контроля рукой. Главным определяющим качеством износостойкости и прочности будущего паркетного покрытия является правильность подбора паркета, лака и подосновы. Фирмы, продукция которых вас не разочарует точно: Teka (Германия), Grabo и Befag (Венгрия), Upofloor (Финляндия), Vito (Австрия), Ekowood (Эковуд), Forbo (Швеция), Magic Flor (Бельгия). Здесь многое зависит от степени желания сэкономить. Это можно сделать на отдельных слоях подосновы. К примеру, можно безболезненно полипропиленовую гидроизоляционную пленку заменить более недорогим полиэтиленовым аналогом. Или водостойкую фанеру поменять на обычный ДСП. Но об экономии на качестве паркетных элементов не может быть и речи.
Но об экономии на качестве паркетных элементов не может быть и речи.
Способы укладки паркета на пол.
Укладка паркета требует высокой точности. Потому как это влияет не только на красоту и точность достижения желаемого рисунка, но и циклевать точную укладку приходится на 0,2 — 0,3 мм, а ошибки приводят к необходимости снимать до 0,8 — 1,0 мм верхнего слоя дорогого материала.
Эстетичность паркетного пола в помещении определяется:
Во-первых: интерьерными решениями помещения;
Во-вторых: мебелью, ее цветом и фактурностью;
В-третьих: фактурностью и рисунком самого паркета.
Все три составляющих должны образовать общую картину, взаимодополнения друг друга. Для облегчения эстетичной органичности паркетного пола или стен производители предлагают два вида паркета:
• радиальный распил отличается классичностью приближающейся к скучности;
• тангенциальный распил имеет куда более разнообразный рисунок, некое подобие многослойной витиеватости структуры древесного волокна.
С учетом данных особенностей работают многие современные дизайнеры и помещения получаются особого благородного, фантазийного и неожиданного богатого интерьерного исполнения. Существует несколько техник укладки паркетных элементов. К самым распространенным видам относят елочку, плетенку, палубу и шахматы, либо мозаичная или художественная. К примеру, самой простой техникой укладки паркета является вид под названием «палубная», которую можно ориентировать и по диагонали, и с учетом параллельности к стенам, но и ее лучше доверить специалисту.
Технология укладки паркета несколькими этапами.
Самая надежная укладка производиться на многослойную основу из:
• ровной и сухой стяжки;
• гидроизоляции;
• фанера, которая укладывается отдельными листами (с зазорами в 4 мм) и обязательно фиксируется на стяжку.
Теперь на фанеру наносят клей и определенным образом (в соответствии с выбранной техникой укладки) размещают паркетные планки. Обязательно точное соблюдение соединения «паз-гребень». Строго следите, чтобы в сочленение планок не попадал клей, что вызовет образование сложных зигзагообразных растрескиваний. Через определенные промежутки уложенные элементы фиксируют для прижатия на весь период скрепления их клеем. И так до края помещения. У стен обязателен зазор не менее 1 см, который по окончанию работы заполняют герметичным, но эластичным составом.
Строго следите, чтобы в сочленение планок не попадал клей, что вызовет образование сложных зигзагообразных растрескиваний. Через определенные промежутки уложенные элементы фиксируют для прижатия на весь период скрепления их клеем. И так до края помещения. У стен обязателен зазор не менее 1 см, который по окончанию работы заполняют герметичным, но эластичным составом.
Помимо представленных слоев многослойная подоснова может включать дополнительно звуко- и теплоизолирующие дополнения под фанерными щитами. Далее готовый паркетный пол шлифуют (при необходимости) при помощи специальных машин, лучше профессионального спектра исполнения. Что позволяет не только добиться тонкой и максимально ровной шлифовки, но и максимально эффективного сбора древесной пыли. Иначе после шлифовки требуется дополнительное удаление пыли.
Далее идет лакировка, воскование или обработка специальными составами, к примеру, маслом или морилками. Сегодня выбор данных средств огромен. Воскование паркета снимает необходимость периодичного циклевания каждые 5 — 8 лет. Возможно, сделать и искусственное старение нового паркетного пола, называемое патинирование, и придать матовость или глянец, но не стоит забывать о том, что все химические реагенты разрушают паркет, следовательно, снижают его износостойкость.
Возможно, сделать и искусственное старение нового паркетного пола, называемое патинирование, и придать матовость или глянец, но не стоит забывать о том, что все химические реагенты разрушают паркет, следовательно, снижают его износостойкость.
Нанесение лака лучше всего делать при помощи кисти. Самыми качественными и безвредными как для человека, так и для паркета (без содержания кислоты, вызывающей потемнение лака) считаются финские, немецкие, американские или шведские лаки.
Рекомендации по уходу за паркетным полом:
1. Старайтесь максимально оберегать ваш паркет от попадания на него прямой в воды или любых химических реагентов (причем в растворах любой концентрации). Если нежелательное попадание все же произошло, то необходимо тщательное промакивание реагента или воды, мягким материалом насухо;
2. Мытье паркетного пола производиться с минимальным применением воды. Лучше использовать специальные средства;
3. Соблюдайте контроль влажности в пределах 50 — 70% при температуре 20 — 22 грд. С, зимой и осенью нежелательно открывание окон в помещениях с паркетным полом;
Соблюдайте контроль влажности в пределах 50 — 70% при температуре 20 — 22 грд. С, зимой и осенью нежелательно открывание окон в помещениях с паркетным полом;
4. Лаковое покрытие паркета любого типа желательно обновлять через 3 — 4 года, а циклевать через 5 — 8 лет, в зависимости от состояния паркета;
5. Сколь бы прочен и качественен не был бы ваш паркет его необходимо оберегать от царапин, ударов как острыми, так и тяжелыми предметами. Рекомендуют мебель устанавливать на платформы, в помещении носить только мягкую обувь.
Только соблюдение столь простых и незамысловатых ограничений позволит вам долгие годы наслаждаться прекрасным паркетным покрытием вашего пола.
Штучный дубовый паркет
Традиционное, всем известное напольное покрытие. Но в чем его особенности? От чего зависит его срок службы, каковы параметры качества штучного паркета, известно далеко не всем. Разбираемся.
На фото:
Основные характеристики
Внешний вид паркетной плашки. Штучный паркет выпускается плашками — небольшими дощечками, готовыми к укладке и дальнейшей обработке. Их лицевая поверхность гладкая, а нижняя может быть как гладкой, так и с насечкой. Кромки паркетин профилированы, что позволяет стыковать их по принципу паз — гребень. Сообразно расположению гребня различают левые и правые плашки. Материал продают упакованным в термоусадочную пленку, снимать которую рекомендуется непосредственно перед укладкой.
Штучный паркет выпускается плашками — небольшими дощечками, готовыми к укладке и дальнейшей обработке. Их лицевая поверхность гладкая, а нижняя может быть как гладкой, так и с насечкой. Кромки паркетин профилированы, что позволяет стыковать их по принципу паз — гребень. Сообразно расположению гребня различают левые и правые плашки. Материал продают упакованным в термоусадочную пленку, снимать которую рекомендуется непосредственно перед укладкой.
Штучный паркет можно укладывать разными способами. Примеры укладки: «Квадраты», «Ёлочка», «Палуба», «Голландский узор».
Укладка «Квадраты».Стандартные размеры. Длина элементов штучного паркета варьируется в пределах от 150 до 600 мм, ширина — от 30 до 90 мм. Наиболее технологичны в укладке и популярны образцы, длина которых составляет от 280 до 420 мм, ширина — до 70 мм. Что касается толщины, то в основном производятся 15–18-миллиметровые планки. Есть в продаже и более — массивный паркет — толщиной 22–25 мм. Это достаточно дорогой материал.
Это достаточно дорогой материал.
Сегодня на рынке появился штучный паркет длиной от 450 до 1200 мм, при ширине 90 мм и толщине 15–16 мм, что связано с увеличением площади квартир новых домов.
Срок службы
Вопросы качества. Качественные паркетные планки должны иметь хорошую геометрию, то есть состыковываться на ровной поверхности без зазоров и перепадов по высоте. ГОСТ регламентирует влажность древесины — 9% (плюс-минус 3%), которая благодаря герметичной упаковке должна сохраняться непосредственно до момента укладки. Разумеется, от качества напольного покрытия зависит красота долговечность пола.
На фото:
Идеальная укладка — плашки с хорошей геометрией соединятся без усилий и без щелей.
Толщина важна! Если длина и ширина паркетины имеют отношение в основном к декору и к удобству монтажа, то ее толщина, а точнее, ее слой износа, определяет потенциальный срок службы паркета.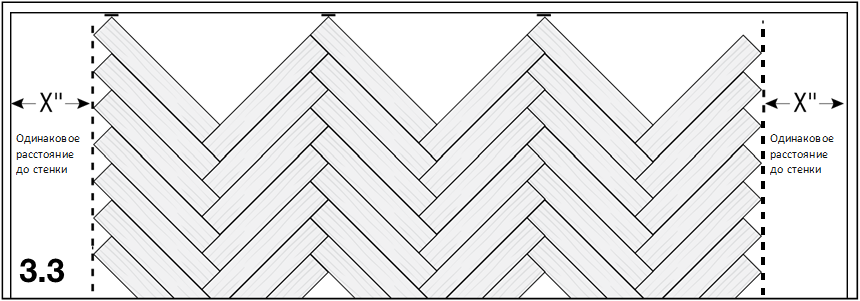 Слой износа — это расстояние от лицевой стороны плашки до верхней части паза или гребня. Слой износа для плашки толщиной 15 мм составляет обычно 7 мм, для плашки толщиной 22 мм — 9 мм.
Слой износа — это расстояние от лицевой стороны плашки до верхней части паза или гребня. Слой износа для плашки толщиной 15 мм составляет обычно 7 мм, для плашки толщиной 22 мм — 9 мм.
Шлифовка или циклевка? Паркетный пол рекомендуют шлифовать примерно раз в 8–10 лет. Шлифовка — это современная бережная технология, в ее процессе снимается верхний слой лака и небольшой слой древесины всего 0,3 – 0,8 мм (в отличие от циклевки, при которой используются режущие инструменты и удаляется до 1,5 мм). Таким образом, паркет со слоем износа 9 мм может прослужить около 100 лет.
На фото:
Выбирая штучный паркет для помещений разного назначения, нужно учитывать, что на срок службы паркета влияют условия его эксплуатации.
«Паркетные» породы древесины. Штучный паркет изготавливают в основном из древесины лиственных пород, которые отличаются более высокой твердостью и износостойкостью по сравнению с хвойными. В свою очередь, эта древесина делится на местную (из Центральной Европы) и экзотическую (с других континентов). К первой группе относятся дуб, бук, ясень, клен, и т.д. Ко второй — махагони, мербау, тик, венге, ироко, пр. Хвойные породы (лиственница, тис) применяются ограничено. Наиболее долговечен паркет из дуба, тика, мербау.
В свою очередь, эта древесина делится на местную (из Центральной Европы) и экзотическую (с других континентов). К первой группе относятся дуб, бук, ясень, клен, и т.д. Ко второй — махагони, мербау, тик, венге, ироко, пр. Хвойные породы (лиственница, тис) применяются ограничено. Наиболее долговечен паркет из дуба, тика, мербау.
На фото:
Дубовый паркет отличают долголетие и устойчивость к гниению, о чем свидетельствуют хорошо сохранившиеся паркеты усадьбы Кусково, Эрмитажа, Петергофского дворца.
размеры с пробковой подложкой на пол, модели паркета 20 и 10 мм
В квартирах, где идет борьба за каждый сантиметр высоты помещения, толщина паркетной доски с учетом стяжки и подложки имеет немаловажное значение. Точность в выборе необходима, чтобы не возникли проблемы со стыковкой дверных порожков или расчете нагрузки при укладке на лаги (закрепление на деревянную обрешетку или бруски).
Объемные характеристики оказывают влияние на скорость и сложность монтажа, шумоизоляцию, теплоту пола, длительность эксплуатации и возможность реставрации напольного покрытия.
Толщина паркетной доски
Паркетная доска бывает двух видов: массивная и сэндвич. В зависимости от производителя толщина ее обычно колеблется от 7 до 26 мм. Чем незначительнее высота поперечного среза планки, тем дешевле обойдется всё напольное покрытие.
Массивная доска
В классическом варианте толщина – от 18 до 20 мм, на рынке можно встретить и 15-16 мм. Выпускается как с финишной обработкой, так и без неё. Незаменима при укладке на лаги.
Изготавливается:
- из цельной древесины твердолиственных пород – от обычного паркета отличается только размерами;
- с двухслойной системой планки – сочетание двух слоев древесных пород, соединение дерева с качественной фанерой.

Сэндвич
Производят из нескольких древесных слоев с перпендикулярным по отношению друг к другу расположением волокон. Между собой элементы скреплены клеем. Паркетные доски сэндвич выпускаются с обязательной финишной отделкой.
Многослойная структура позволяет уменьшить возможное изменение линейных размеров, деформацию пола при температурных перепадах или резкой смене влажности. Чередование направлений волокон обеспечивает амортизацию покрытия при ходьбе, снижает напряжение на систему крепления планок между собой и к подложке. (фото)
Структура
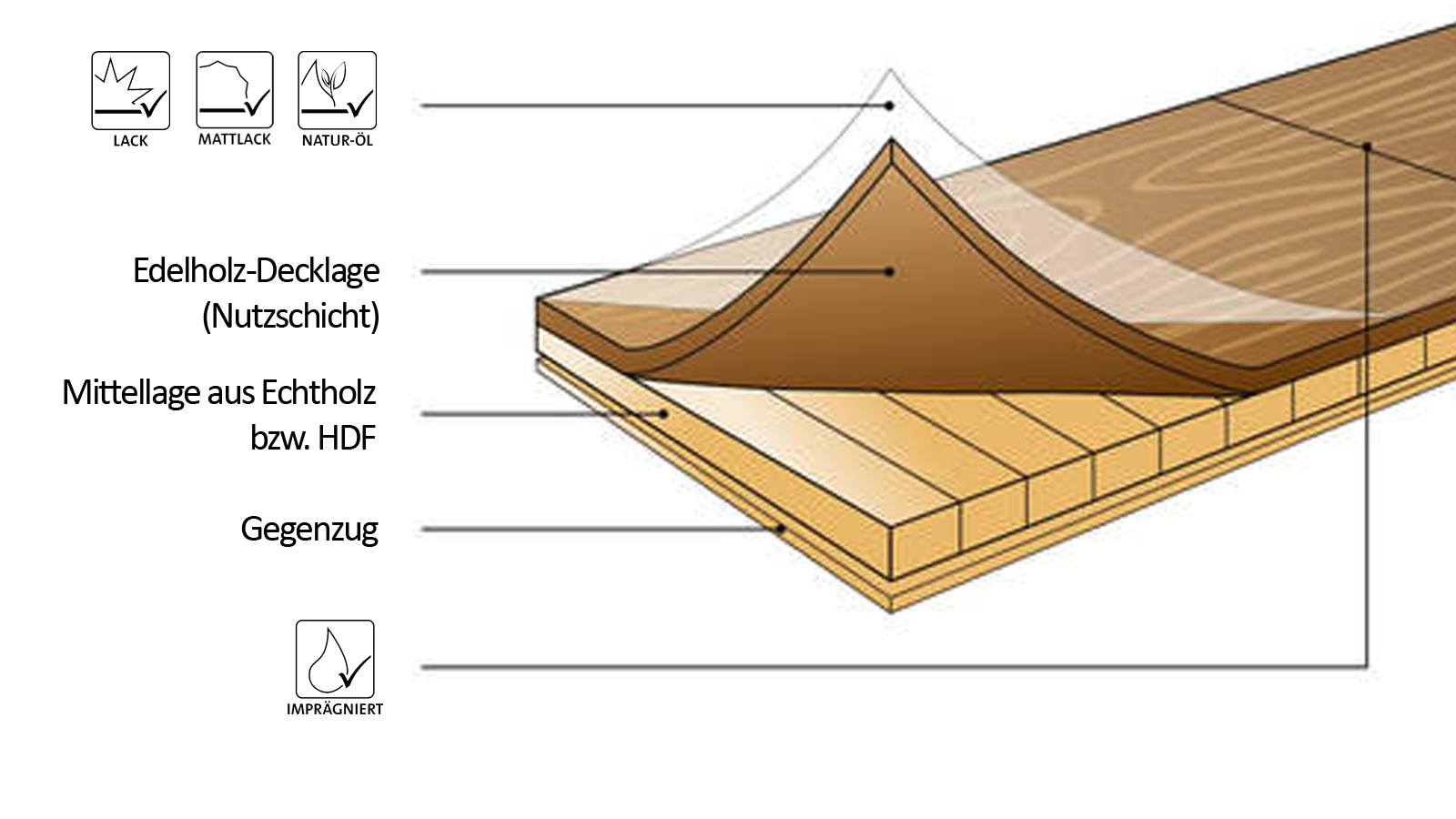
Трехслойная паркетная доска имеет следующую структуру:
- Внешний слой состоит из лакового покрытия или масляной пропитки. Такая обработка увеличивает защитные свойства и износостойкость рабочей поверхности и не влияет на определение толщины планки.
- Верхний слой – от 0,5 до 6 мм, изготавливается из ценных пород древесины. Они должны сочетать в себе и красоту, и высокую прочность. Наиболее часто используются дуб, бук, клен, вишня, ольха, венге и другие. Приятный внешний вид усиливают браширование, отбеливание, строгание и термообработка.
- Средний слой – 8-9 мм. На него приходится основная механическая нагрузка, поэтому используется древесина хвойных пород с высокой плотностью. Существует в двух вариантах:
- в виде цельной плиты – усиливает жесткость;
- склеенных между собой ламелей (реек) – придает гибкость паркетным доскам, что позволяет нивелировать шероховатости чернового пола.
 Такая обработка увеличивает защитные свойства и износостойкость рабочей поверхности и не влияет на определение толщины планки.
Такая обработка увеличивает защитные свойства и износостойкость рабочей поверхности и не влияет на определение толщины планки.По торцам среднего слоя располагаются элементы крепления планки – шпунтированной или замковой системы.
- Нижний слой – 1,5 мм, производят в виде цельной пластины, выполненной из отходов хвойных пород или фанеры. Основание обеспечиваетдополнительную жесткость и держит на себе всю конструкцию планки. Для защиты от влаги пропитывается водоотталкивающими средствами.
Цена
Цена древесины лиственных пород всегда выше, чем хвойных. Это связано со сложностью технологической обработки, редкостью вида растения и временем, необходимым для его выращивания до зрелого состояния. На прочность и долговечность паркетной доски порода не влияет.
Сочетание дорогих с более дешевыми породами дерева значительно снижает цену на напольное покрытие, поэтому при равной толщине цена на массив всегда будет выше, чем на сэндвич.
Долговечность
Толщина напрямую влияет на продолжительность жизни паркетных досок
Для массивной доски из цельной древесины при соблюдении всех условий по уходу срок службы длится от 40 до 100 лет.
Максимально допустимый износ планки:
- для штучной (цельной) – до половины своей толщины;
- для двухслойной – 5-7 мм (выдерживает от 4 до 6 шлифовок), остальная часть древесины отвечает за прочность соединения досок между собой.
Для сэндвича средний срок жизни колеблется от 7 до 40 лет.
Предельно допустимый износ непосредственно зависит от толщины верхнего слоя, который у паркетных досок этого вида бывает:
- При общей толщине планки от 0,5 до 10 мм – лицевой слой всего до 2,5 мм. Шлифовка и реставрация не предусмотрены. Срок службы до 8 лет. Рекомендуется использовать в комнатах или подсобках, в которые редко кто-то заглядывает, но полы должны соответствовать стилевому решению всего дома или квартиры. Тонкие паркетные доски незаменимы в ситуациях, когда по иному невозможно организовать порожек или при небольшой высоте помещения.
- От 13 до 16 мм – верхний слой до 4 мм. Это даёт возможность провести 2-3 шлифовки. Покрытие подходит для комнат с небольшой проходимостью: спальня, кабинет, гостиная.
- При 20-26 мм лицевой слой составляет от 3,6 до 6 мм. Такие доски справляются с высокими нагрузками даже в общественных учреждениях: школах, поликлиниках, кафе, конференц-залах. В квартирах их используют для оформления кухни или коридора. Самые крупные образцы, от 22 мм, идеально подходят для восстановления старинных построек, при строительстве или ремонте дач, загородных домов. Шлифовка в зависимости от верхнего слоя может проводиться 3-5 раз. Срок службы от 15 до 40 лет.
- При 35-40 мм – толщина рабочего слоя достигает максимальных значений, длительность использования от полувека. Такие паркетные покрытия используют в концертных и спортивных залах, гостиницах. Цена несравнимо выше, чем на обычные.
 Шлифовка и реставрация не предусмотрены. Срок службы до 8 лет. Рекомендуется использовать в комнатах или подсобках, в которые редко кто-то заглядывает, но полы должны соответствовать стилевому решению всего дома или квартиры. Тонкие паркетные доски незаменимы в ситуациях, когда по иному невозможно организовать порожек или при небольшой высоте помещения.
Шлифовка и реставрация не предусмотрены. Срок службы до 8 лет. Рекомендуется использовать в комнатах или подсобках, в которые редко кто-то заглядывает, но полы должны соответствовать стилевому решению всего дома или квартиры. Тонкие паркетные доски незаменимы в ситуациях, когда по иному невозможно организовать порожек или при небольшой высоте помещения. Срок службы от 15 до 40 лет.
Срок службы от 15 до 40 лет.Промежуточный ремонт паркетных покрытий наступает по мере износа лака или масляной пропитки. При соблюдении условий эксплуатации и изначальном качестве внешнего слоя потребность в косметическом вмешательстве наступит в промежуток от 2 до 7 лет. Повторить заводское качество в домашней обстановке невозможно, поэтому необходимость в шлифовке пола и его обработке лаком будет происходить раньше, чем в первый раз, периодичность между циклевками будет значительно сокращаться.
Для повышения эластичности и обеспечения вентиляции пола в толстых досках с тыльной стороны имеются надрезы или пазы – продух.
 Величина этих углублений не учитывается при определении толщины и никакого влияния на долговечность изделия не оказывают.
Величина этих углублений не учитывается при определении толщины и никакого влияния на долговечность изделия не оказывают.Толщина стяжки
Стяжка представляет собой верхнюю часть конструкции чернового пола, она необходима для выравнивания поверхности. От её гладкости во многом зависит качество укладки и долговечность эксплуатации напольного покрытия. Допустимый перепад высоты на один квадратный метр – 3 мм, погонный – 2 мм.
По толщине различают три типа стяжки:
- до 2 см – заливка с применением самовыравнивающихся смесей;
- до 7 см – из железобетона с использованием армирующей сетки или арматуры;
- до 15 см – из монолита с арматурой внутри, это одновременно и пол, и фундамент дома.

Толщина планки для «теплых полов»
Паркетная доска толщиной свыше 10 мм способна выдержать увеличение температуры до отметки в +27С. Лаковый слой и прочность сэндвича не изменятся. Однако нагревание должно проходить медленно, чтобы избежать разрушения древесины. Таким требованиям может соответствовать только водная система. Толщина стяжки от труб для равномерного обогрева – не менее 5 см. При монтаже обязательно должна быть проложена гидроизоляция. Вариант укладки один – приклеивание к стяжке.
Для «теплых полов» не используются паркетные доски с толщиной планки:
- до 10 мм – не выдерживают механической нагрузки, от перепадов температур появляются трещины, уменьшается и без того короткий срок эксплуатации пола;
- от 20 мм – из-за низкой теплопроводимости, на обогрев приходится тратить значительно больше электроэнергии.

Рекомендованным вариантом покрытия для пола с подогревом считаются планки – 13-15 мм.
Толщина подложек
Основная функция подложек – сгладить неровности, увеличить амортизацию, устранить гулкие звуки при ходьбе, утеплить пол, в некоторых случаях усилить гидроизоляцию.
Виды подложек:
- синтетические – пенополиэтиленовые, фольгированные, пенополипропиленовые;
- натуральные – пробковые, хвойные – требуется пароизоляция;
- композитные – Tuplex, битумно-пробковые, резино-пробковые, «Парколаг» (запрещен из-за токсичности в некоторых странах).
Выпускаются с толщиной от 1 до 12 мм. Выбираются, исходя из ровности поверхности стяжки и поперечного сечения доски. Нарушение допустимого предела толщины подложки приводит со временем к появлению зон продавливания и уплотнений, за счет чего увеличивается перепад допустимых высот. Нагрузки на замковую систему и верхний слой планки становятся критическими, появляются трещины, разрушается лаковое покрытие, ломаются соединительные элементы.
Выбираются, исходя из ровности поверхности стяжки и поперечного сечения доски. Нарушение допустимого предела толщины подложки приводит со временем к появлению зон продавливания и уплотнений, за счет чего увеличивается перепад допустимых высот. Нагрузки на замковую систему и верхний слой планки становятся критическими, появляются трещины, разрушается лаковое покрытие, ломаются соединительные элементы.
Вариант расчета толщины подложки, отталкиваясь от параметров паркетной доски:
- для планок до 7 мм – 2 мм;
- для планок от 8 до 16 мм – от 2 до 4 мм, оптимальный – 3 мм;
- для планок от 10 мм – от 4 до 10 мм.
Применение подложек в зависимости от их толщины:
- 2 мм – выравнивает незначительные неровности, является лучшим выбором в случаях идеальной стяжки под паркетную доску до 16 мм. Может использоваться во всех помещениях.
- 3 мм – подходит для выравнивания небольших перепадов высот и утепления полов под паркетную доску до 18 мм, оптимальный выбор для квартир в многоэтажках.
- 4 мм – по характеристикам практически совпадает с предыдущим значением для вспененных и композитных материалов. Не рекомендуется применять в местах с большой проходимостью: на кухне, в коридоре, прихожей.
- От 5 мм и выше – используется в случаях применения толстых планок и в мало посещаемых местах: кладовых, чуланах, гардеробной, на обустроенном чердаке загородного дома.
 Может использоваться во всех помещениях.
Может использоваться во всех помещениях.При качественно выровненной стяжке оптимальная толщина подложки под паркетную доску – 2-3 мм.
В качестве подложки очень часто применяется калиброванная фанера толщиной от 1 до 2 см. Специалисты советуют подбирать в этом случае толщину листов на 5 мм тоньше паркетной доски. Для снижения последствий от сезонных перепадов температур и защиты от влаги под фанерное основание прокладывается пароизоляционная пленка толщиной 0,2 мм. В помещениях с повышенной сыростью или влажном климате вместо пленки используют специальные гидроизоляционные покрытия.
Для снижения последствий от сезонных перепадов температур и защиты от влаги под фанерное основание прокладывается пароизоляционная пленка толщиной 0,2 мм. В помещениях с повышенной сыростью или влажном климате вместо пленки используют специальные гидроизоляционные покрытия.
О том, как выбрать паркетную доску, смотрите в следующем видео.
выбор размера с учетом пробковой подложки для паркета, модели для пола 10 и 20 мм
Разновидностей материалов для напольного покрытия есть много. Одним из самых качественных и оптимальных на протяжении многих лет является паркет, который можно встретить не только в жилых помещениях, но и в ресторанах, отелях, офисах и других зданиях. Такой материал обладает рядом преимуществ, которые и привлекают потребителя, поэтому популярность напольного покрытия не угасает.
Одним из самых качественных и оптимальных на протяжении многих лет является паркет, который можно встретить не только в жилых помещениях, но и в ресторанах, отелях, офисах и других зданиях. Такой материал обладает рядом преимуществ, которые и привлекают потребителя, поэтому популярность напольного покрытия не угасает.
Есть несколько разновидностей паркетной доски, каждая из которых имеет свои характеристики, особенности и достоинства, о которых полезно узнать перед покупкой. Укладка происходит с подложкой, так как она является неотъемлемой частью процесса.
Если говорить о положительных качествах материала, следует отметить то, что благодаря ему можно быстро обустроить помещение, ведь монтаж не займет много времени. Паркетная доска является натуральной, и многие потребители предпочитают ее из-за этого показателя.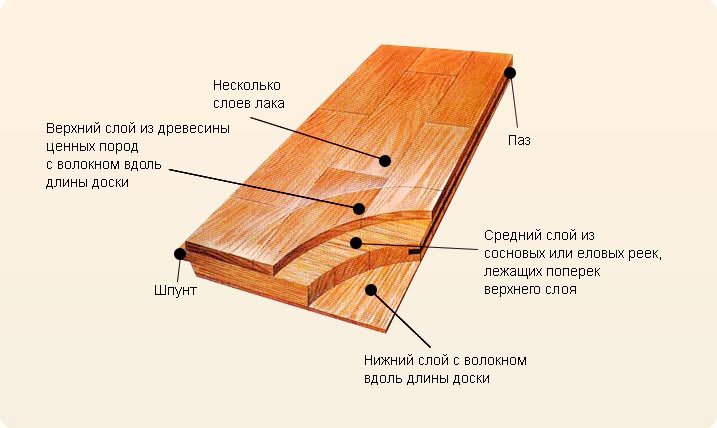 Изделие отлично справляется с перепадами температуры, в нем не появляются щели и трещины, поэтому срок эксплуатации покрытия будет длительным. Для этого материал покрывается специальными смесями и лаками, чтобы улучшить характеристики.
Изделие отлично справляется с перепадами температуры, в нем не появляются щели и трещины, поэтому срок эксплуатации покрытия будет длительным. Для этого материал покрывается специальными смесями и лаками, чтобы улучшить характеристики.
Презентабельность паркетной доски неоспорима, так как она бывает разных текстур, ведь изготавливается из тех или иных пород древесины. Конечно, при всех этих положительных качествах, нельзя забывать о правильном и регулярном уходе за покрытием, а также избегать повышенной влажности в помещении, чтобы материал не испортился и не деформировался.
Строение паркетной доски и ее размеры
Покрытие состоит из слоев разной древесины, для лицевого используют ценные породы. Отличается верхний слой для пола толщиной, которая может варьироваться от трех до шести миллиметров. Именно этот параметр влияет на то, какое количество шлифовок может пережить напольное покрытие, ведь чем больше показатель, тем чаще можно будет заниматься реставрацией паркета.
Именно этот параметр влияет на то, какое количество шлифовок может пережить напольное покрытие, ведь чем больше показатель, тем чаще можно будет заниматься реставрацией паркета.
Внутри материала укладывается древесноволокнистая плита, у которой высокая плотность, так как толщина составляет 9 мм. Чаще всего для нее используются хвойные ламели, ведь они одни из наиболее доступных. На устойчивость покрытия влияет толщина паркетной доски, поэтому при покупке на этот параметр нужно обратить особое внимание.
Перед вами откроется большой выбор, так как вы можете сделать пол толщиной от 7 до 25 мм. Но при этом следует учитывать важные аспекты, а именно – индивидуальные характеристики помещения, где будет происходить укладка доски.
Если вы хотите минимизировать шум, рекомендуется выбирать покрытие, которое отличается большой толщиной и твердостью. Такой пол прослужит долгие годы и сможет перенести много шлифовок. Но если речь идет о комнате с невысокими потолками, здесь доска должна быть не такой толстой, поэтому покрытие будет упругим.
Такой пол прослужит долгие годы и сможет перенести много шлифовок. Но если речь идет о комнате с невысокими потолками, здесь доска должна быть не такой толстой, поэтому покрытие будет упругим.
В некоторых ситуациях квалифицированные специалисты рекомендуют использовать дополнительную прослойку, к примеру, фанеру. Это повлияет на денежные затраты, но и даст определенные преимущества.
Отличия паркета разной толщины
Параметры покрытия играют большую роль, ведь от них зависит показатель долговечности, а также переносимость изделием ремонта. Если выбрать слишком толстую доску, может возникнуть функциональная и эстетическая проблема касательно дверных проемов. В тонких изделиях лицевой слой изготавливается из благородных пород, но они быстро истираются, если помещение часто эксплуатируется. Такой пол не получится циклевать, поэтому обратите на это внимание сразу.
Такой пол не получится циклевать, поэтому обратите на это внимание сразу.
Если необходимо обустроить покрытие для офиса или кабинета, здесь предпочтительней доска, толщина которой достигает 1,5 см. Обрабатывать материал можно до трех раз, так как верхний слой равен 4 мм. Для комнат с большой нагрузкой и активностью рекомендуется приобретать толстую паркетную доску, размеры которой 20 мм, где лицевая часть составляет 6 мм. Такой пол можно ремонтировать до пяти раз.
Выбор параметров покрытия для разных помещений
Сделать это можно благодаря характеристикам групп материала. Начинать следует с доски, минимальная толщина которой может быть 8 мм и достигает 10 мм. Такой тип настоятельно не рекомендуется шлифовать, так как древесина не выдержит обработки. Верхний слой изготавливается из ценных пород. Актуальность материала предпочтительна для помещений, в которых нельзя сделать порожки.
Начинать следует с доски, минимальная толщина которой может быть 8 мм и достигает 10 мм. Такой тип настоятельно не рекомендуется шлифовать, так как древесина не выдержит обработки. Верхний слой изготавливается из ценных пород. Актуальность материала предпочтительна для помещений, в которых нельзя сделать порожки.
Следующий вариант – от 12 до 16 мм. Верхний слой составляет 4 мм, поэтому шлифовать такую поверхность максимально можно три раза. Подобное покрытие нередко встречается в жилых помещениях, где наблюдается небольшая проходимость, нет значительных нагрузок. Это может быть спальня или детская комната. Стоимость такого материала доступная, а качество на высоте. Покрытие с 15 мм толщины считается одним из самых ходовых.
Паркетная доска с параметром до 20 мм пользуется спросом там, где планируется большая проходимость, поэтому рекомендуется такой пол укладывать на кухнях, в холлах, а также общественных местах. Благодаря таким габаритам материал выдерживает многочисленные шлифовки, так как обладает большой долговечностью.
Благодаря таким габаритам материал выдерживает многочисленные шлифовки, так как обладает большой долговечностью.
И самым прочным покрытием считается доска от 22 до 25 мм. Здесь важно отметить, что ее стоимость гораздо выше, чем остальные виды. Такой материал используют во время реставрации старых зданий, где необходимо сохранить красоту и выдержать определенный стиль в интерьере.
Нельзя забывать о подложке, так как она входит в расчет толщины материала. И перед тем, как выбрать доску, необходимо определиться со способом укладки. Для этого лучше проконсультироваться с квалифицированным специалистом, который разбирается в этой области, и может дать полезные советы, а также ответить на вопросы по монтажу.
Как правильно выбрать толщину?
Если вы уже давно задаетесь этим вопросом, следует обратить внимание на несколько рекомендаций. К каждому виду материала есть детальное описание характеристик и параметров, а также указана сфера применения. Вы можете уточнить способ укладки.
К каждому виду материала есть детальное описание характеристик и параметров, а также указана сфера применения. Вы можете уточнить способ укладки.
Не забывайте, после настила пол станет несколько выше, и здесь большую роль играет не столько паркетная доска, сколько величина подложки с выравнивающим слоем.
К популярным видам подложек относится пробковый материал, который обладает рядом положительных характеристик. У него есть свои особенности и преимущества, которые привлекают большое количество потребителей.
Такое покрытие экологичное, обладает антистатическим эффектом, справляется с повышенной влажностью, пробка не подвергается горению, а срок эксплуатации достигает пятнадцати лет. Толщина подложки выбирается от 1,5 до 6 мм. Цена на такую продукцию предлагается оптимальная.
Расчет количества материала
Это важная часть подготовки к ремонту, так как необходимо приобрести достаточно паркетной доски, чтобы не пришлось потом дополнительно заказывать, ведь придется ждать. В любом случае вы сможете без проблем продать оставшиеся запасы по выгодной цене. А чтобы приобрести сразу нужное количество, необходимо учитывать ряд критериев.
В любом случае вы сможете без проблем продать оставшиеся запасы по выгодной цене. А чтобы приобрести сразу нужное количество, необходимо учитывать ряд критериев.
В первую очередь, главную роль играет размер помещения, поэтому необходимо уточнить параметры длины, ширины, чтобы знать площадь комнаты, где будет проводиться укладка. Что касается габаритов паркетной доски, они указаны в детальном описании, поэтому вы сможете легко все рассчитать. Важно заранее определиться со способом монтажа, так как для ровной укладки количество отходов будет меньше в отличие от диагональной.
Как выбирается дизайн напольного покрытия из паркетной доски?
Это важный момент в оформлении интерьера, ведь существует много разновидностей материала. Для начала необходимо определиться с типом породы древесины, которая вас привлекает своей текстурой и оттенком. Вы можете сделать геометрический пол, либо выбрать вариант гораздо сложнее, и специалисты создадут индивидуальный рисунок, чтобы подчеркнуть стиль интерьера.
Вы можете сделать геометрический пол, либо выбрать вариант гораздо сложнее, и специалисты создадут индивидуальный рисунок, чтобы подчеркнуть стиль интерьера.
В таких вопросах необходимо руководствоваться своими пожеланиями и предпочтениями, главное – выбрать качественный материал для напольного покрытия с необходимыми параметрами толщины.
Обратитесь за помощью к профессионалам, получите консультацию, изучите детальную информацию, и найдете именно то, что нужно. Успешного ремонта!
О том, как выбрать паркетную доску, смотрите в следующем видео.
Уплотнение / соединение паркетных напильников | Крис Финлейсон | bigspark
Мы можем контролировать разделение (размер файла) результирующих файлов, если мы используем алгоритм сжатия с возможностью разделения, такой как snappy.
Давайте рассмотрим пример оптимизации плохо уплотненного раздела таблицы в HDFS. По сути, мы будем читать все файлы в каталоге с помощью Spark, перераспределять их до идеального числа и перезаписывать.
Рассмотрим каталог HDFS, содержащий 200 файлов размером ~ 1 МБ и настроенный dfs.размер блока 128 МБ
Давайте сгенерируем несколько паркетных файлов для тестирования:
из pyspark.sql.functions import litdf = spark.range (100000) .cache ()
df2 = df.withColumn ("partitionCol", lit ("p1 "))
df2.repartition (200) .write.partitionBy (" partitionCol "). SaveAsTable (" db.small_files ")
И просмотрите выходные данные (используя настроенную версию инструмента под названием hdfs-shell)
200 файлов создано в разделе p1 207,8 МБ размер исходного файла сгенерированоДля нас просто вычислить оптимальное количество файлов как:
(общий размер файла / сконфигурированный размер блока) = идеальное количество файлов
В этом примере:
(207 / 128) = 1.61
В качестве коэффициента передела принимаем округленное значение (2).
Простой фрагмент pyspark для этого:
def get_repartition_factor (dir_size):
block_size = sc._jsc.hadoopConfiguration (). Get («dfs.blocksize»)
return math.ceil (dir_size / block_df = 2) # возвращает spark.read.parquet («/ path / to / source»)
df.repartition (get_repartition_factor (217894092))
.write
.parquet («/ path / to / output»)
Приведенный выше код будет читать 200 файлы в фрейм данных, перераспределение на основе оптимального расчетного значения и вывод 2 файлов одинакового размера.
Также можно использовать .coalesce () для того же эффекта и для более производительной операции записи, однако результирующие файлы не будут иметь одинаковый размер — поэтому они менее оптимальны для дальнейшей обработки.
Создано 2 файла одинакового размераВ результате размер каждого файла составляет 113 МБ, что приближается к оптимальному размеру dfs.blocksize.
Регулярное сжатие постоянных файлов становится все более важным упражнением по управлению данными. Это ключ к поддержанию оптимальной производительности чтения и снижению накладных расходов на управление метаданными.
При незначительных усилиях по разработке можно создать процесс искателя для постепенного обхода всех таблиц и их разделов в пакете данных — получение общего размера каждого каталога и вычисление идеального количества файлов по сравнению с размером блока хранения — принятие мер если состав не оптимален.
Когда паркетные колонны становятся слишком большими
Эта статья предназначена для инженеров, которые используют Apache Parquet для обмена данными и не хотят неприятных сюрпризов.
На самом деле название выше неправильное.На самом деле должно быть написано «Когда возникают ошибки переполнения целых чисел», но мы к этому и вернемся. Этот пост о файловой структуре Parquet, ее особенностях, хотя и не уникальных, о том, как пользователи Python / Pandas этого формата могут захотеть настроить некоторые параметры и как Vortexa помогает с открытым исходным кодом.
Что такое паркет?
Apache Parquet — это файл в формате столбцов. Общие файлы, к которым мы привыкли, такие как текстовые файлы, CSV и т. Д., Хранят информацию по одной строке (или записи, если хотите) за раз.Это легко осмыслить, и у него есть некоторые преимущества, но есть и преимущества в повороте этой модели и хранении данных столбец за столбцом. Чтобы объяснить их, нам нужно сначала погрузиться в структуру.
Паркетный файл имеет такую структуру (с некоторыми упрощениями):
- Файл заканчивается нижним колонтитулом, содержащим данные индекса, где в файле можно найти другие данные.
- Файл разделен на группы строк, которые, как и следовало ожидать, содержат группы строк.
- Группа строк содержит информацию о каждом столбце для набора строк.
- Каждый столбец содержит метаданные и данные поиска по словарю, а также данные для определенного отдельного столбца для количества строк, хранящихся непрерывно.
- Сами данные столбца разбиты на страницы. Страницы неделимы, т. Е. Должны быть полностью декодированы при обращении к ним и могут иметь сжатие.
На приведенной выше диаграмме показано, как это вложено, с подробностями о последующих группах строк, столбцах и т. Д.опущено.
Так зачем тратить столько времени?
- Данные для данного столбца хранятся вместе — вероятно, многие значения похожи, и эта структура обеспечивает гораздо лучшее сжатие данных.
- При чтении файла нужно читать и декодировать только интересующие нас столбцы
- Столбцы содержат метаданные со статистикой по их содержимому — мы можем пропустить данные, которые, как мы знаем, нас не интересуют, — известные как предикаты выталкивания вниз.
Все это означает меньше операций ввода-вывода и более быстрое чтение данных за счет более сложных операций записи данных.
Parquet является частью экосистемы Hadoop, и такие инструменты, как Hive и Presto, могут эффективно считывать большие объемы данных, используя их в любом масштабе.
Приключение началось с производства
Среди множества движущихся частей за кулисами Vortexa у нас есть процесс Python, который производит около 6 ГБ вывода в файле Parquet, и последующий процесс Java, который его использует.
Однажды он просто перестал его потреблять, но начал срываться, конструктор ArrayList жаловался на отрицательный параметр размера.Почему?
Итак, что в первую очередь делает инженер в наши дни, когда сталкивается с неясной ошибкой? Поищи в Гугле! Я столкнулся с этой ошибкой Jira, связанной с самой библиотекой Пакета. «Основная» ошибка, обнаруженная с августа 2019 года. Хм.
Двусторонний подход
Я решил заняться двумя делами параллельно:
- Ищите способ исправить производственный процесс — быстро!
- Попытка исправить ошибку сама, внося свой вклад в проект Apache Parquet.
Обход
Я подозревал переполнение 32-битного целого числа со знаком.Файл содержал около 67 миллионов записей, намного меньше 2³¹ = 2,1 миллиарда, но, возможно, что-то еще было не так.
Я получил «parquet-tools» с помощью brew (я использую Mac) и запустил команду «meta» для файла. Я не могу поделиться точными данными, которые я видел для нашего рабочего файла, но я видел это — 98% данных были в первой группе строк. Я мог видеть, что размер этой группы строк превышал 6 ГБ, что намного превышало то, что я думал (ошибочно), было лимитом в 2 байта, учитывая описание в ошибке Jira.
Решение заключалось в том, чтобы при записи файла на Python с использованием Pandas указать аргумент размера группы строк из миллиона записей, таким образом:
data_frame.to_parquet («file.parquet», ** {«engine»: «pyarrow», «row_group_size»: 1000000})
Добавление этого параметра добавило, возможно, 5% накладных расходов к размеру файла, но теперь каждая внутренняя структура файла удобно помещается в пределах 2 ГБ, и проблема переполнения исчезла.
Кажется, что по умолчанию Pandas вообще не разделяет группы строк, что может снизить производительность при использовании Hive, Presto и других технологий.Группы строк, особенно в сочетании с интеллектуальной сортировкой, могут эффективно сегментировать данные.
Исправление ошибки
Я загрузил исходный код библиотеки Apache и разветвил его. У меня был локальный внутренний проект, из которого я мог воссоздать проблему со старым «сломанным» производственным файлом размером 6 ГБ, и я модифицировал его, чтобы получить библиотеку Parquet из этого локального разветвленного проекта вместо Maven.
Покопавшись в отладчике, проследив, где что-то не удалось, я сделал несколько открытий:
- Размеры групп строк не вызывают проблемы переполнения напрямую.
- Размеры столбцов в группе строк вызывают проблему.
- Строковые столбцы обычно хорошо сжимаются, и к ним применяется поиск по словарю (Parquet делает это), но у нас был один столбец, содержащий хэши SHA с очень высокой энтропией, которые не могли сжиматься. В одной группе строк размер этого столбца превышал 4 ГБ.
- Спецификация Parquet не ограничивает эти структуры данных размером 2 ГБ (2³¹ байта) или даже 4 ГБ (2³² байта). Вывод Python / Pandas может быть неэффективным при использовании с некоторыми инструментами, но это не было неправильно .
Таким образом, библиотека была виновата в том, что не смогла прочитать этот действительный, хотя и не очень хорошо структурированный файл, исходящий из Python / Pandas.
Еще несколько экспериментов, и я обнаружил, что наличие большого (более 2 ГБ) столбца не нарушает работу библиотеки Java как таковой, но если бы у нас была следующая группа строк после этих данных, чтение этих данных могло бы нарушиться. Отладка Я обнаружил, что 64-битное значение со знаком считывается из файла parquet как смещение файла, но затем оно преобразовывалось в 32-битное значение со знаком, обрезая значение, размер которого превышал 2³¹.
У нас фактически было 32-битное (или более) положительное число без знака, помещенное в 32-битный знаковый тип, и это сделало наше число отрицательным — это переполнение. Это привело к тому, что конструктор ArrayList был вызван с отрицательным значением размера и исключением, которое все разгадало.
В этом запросе на перенос (утвержденном на момент написания) можно увидеть изменения, внесенные для исправления и модульного тестирования этой проблемы переполнения.
Проблема заключалась в создании адекватного модульного теста, так как эта библиотека не может создать файл, который воспроизводит проблему, так как мы получаем еще одну 32-битную проблему переполнения во время записи файла! Возможно, это менее серьезно, более серьезная проблема заключается в том, что библиотека не может прочитать файл, который является технически правильным.Нам также потребуется примерно 3 ГБ кучи Java для воспроизведения проблемы, что слишком тяжело для модульных тестов во многих конвейерах CI.
Вот мета-вывод parquet-tools для файла, который я создал для воспроизведения проблемы. Почти 38 миллионов строк в первой группе строк, что приводит к увеличению размера строкового столбца, заполненного случайными (несжимаемыми) данными, примерно до 2,1 ГБ, плюс 100000 оставшихся строк во второй группе строк, чтобы читатель мог основывать смещение файла на предыдущих данных. , вызывая ошибку:
Здесь RC = количество строк, а TS = общий размер.Проблема заключается в том, что общий размер «строкового» столбца группы строк 1 составляет 2229232586 байт, за которым следуют некоторые данные в группе строк 2.
Заключение
Vortexa активно использует широкий спектр технологий. Современные системы очень сложны, и если мы найдем способ исправить любые проблемы, внося свой вклад в сообщество открытого исходного кода, мы это сделаем.
Мы нанимаем, присоединяйтесь к замечательной команде, выполняющей удивительную миссию.
Нравится наш контент по науке о данных и технологиях? Возможно вас заинтересует:
Apache Parquet vs.Файлы CSV
Вы наверняка читали о Google Cloud (например, BigQuery, Dataproc), Amazon Redshift Spectrum и Amazon Athena. Теперь вы хотите воспользоваться одним или двумя. Однако, прежде чем углубиться в подробности, вы захотите ознакомиться с возможностями использования Apache Parquet вместо обычных текстовых файлов, файлов CSV или TSV. Если вы не думаете о том, как оптимизировать для этих новых моделей службы запросов, вы выбрасываете деньги в окно.
Что такое паркет Apache?
Apache Parquet — это столбчатый формат хранения со следующими характеристиками:
Apache Parquet разработан для обеспечения эффективного хранения данных в столбцах по сравнению с файлами на основе строк, такими как CSV.
Apache Parquet создан с нуля с учетом сложных вложенных структур данных.
Apache Parquet поддерживает очень эффективные схемы сжатия и кодирования.
Apache Parquet позволяет снизить затраты на хранение данных и повысить эффективность запросов к данным с помощью бессерверных технологий, таких как Amazon Athena, Redshift Spectrum и Google Dataproc.
Parquet — это формат данных с самоописанием, который включает схему или структуру в сами данные.В результате получается файл, оптимизированный для выполнения запросов и минимизации операций ввода-вывода. Parquet также поддерживает очень эффективные схемы сжатия и кодирования.
Паркет и рост облачных хранилищ и интерактивных служб запросов
Рост числа интерактивных сервисов запросов, таких как Amazon Athena, PrestoDB и Redshift Spectrum, упрощает использование стандартного SQL для анализа данных в таких системах хранения, как Amazon S3. Если вы еще не уверены, какие преимущества вы можете получить от этих услуг, вы можете найти дополнительную информацию в этом вводном сообщении об Amazon Redshift Spectrum и в этом сообщении о функциях и преимуществах Amazon Athena.Кроме того, хранилища данных, такие как Google BigQuery и платформа Google Dataproc, могут использовать различные форматы для приема данных.
Выбранный формат данных может существенно повлиять на производительность и стоимость. Мы рассмотрим несколько примеров из этих соображений.
Паркет в сравнении с CSV
CSV прост и вездесущ. Многие инструменты, такие как Excel, Google Таблицы и многие другие, могут создавать файлы CSV. Вы даже можете создать их с помощью любимого инструмента для редактирования текста.Мы все любим файлы CSV, но у всего есть своя цена — даже ваша любовь к файлам CSV, особенно если CSV является вашим форматом по умолчанию для конвейеров обработки данных.
Amazon Athena и Spectrum взимают плату за объем данных, сканируемых за один запрос. (Многие другие сервисы также взимают плату на основе запрашиваемых данных, поэтому это не относится только к AWS.)
Google и Amazon взимают плату за объем данных, хранящихся на GS / S3.
Плата за Google Dataproc зависит от времени.
Невыполнение обязательств по использованию CSV приведет как к техническим, так и к финансовым результатам (не лучшим образом). Вы научитесь любить Parquet так же сильно, как и свой верный CSV-файл.
Пример: CSV-файл объемом 1 ТБ
Следующее демонстрирует эффективность и действенность использования файла Parquet по сравнению с CSV.
Преобразуя данные CSV в столбчатый формат Parquet, а затем сжимая и разбивая их на разделы, вы экономите деньги и получаете выгоду от повышения производительности.В следующей таблице сравнивается экономия, полученная при преобразовании данных в Parquet и CSV.
Если в течение года вы будете использовать несжатые CSV-файлы объемом 1 ТБ в качестве основы для запросов, ваши затраты составят 2000 долларов. При использовании файлов Parquet ваша общая стоимость составит 3,65 доллара. Я знаю, что вам нравятся ваши файлы CSV, но вы любите их или ?
Кроме того, если время — деньги, ваши аналитики могут потратить около пяти минут на ожидание завершения запроса просто потому, что вы используете необработанный CSV.Если вы платите кому-то 150 долларов в час, а они делают это один раз в день в течение года, то они потратили около 30 часов, просто ожидая завершения запроса. Это примерно 4500 долларов в непродуктивное время «ожидания». Общее время ожидания пользователя Apache Parquet? Около 42 минут или 100 долларов.
Пример 2: Parquet, CSV и ваше хранилище данных Redshift
Amazon Redshift Spectrum позволяет выполнять запросы Amazon Redshift SQL к данным в Amazon S3. Это может быть эффективной стратегией для команд, которые хотят разделить данные, когда некоторые из них находятся в Redshift, а другие данные находятся на S3.Например, предположим, что у вас есть около 4 ТБ данных в таблице history_purchase в Redshift. Поскольку к нему обращаются нечасто, имеет смысл выгрузить его на S3. Это освободит место в Redshift, но при этом предоставит вашей команде доступ через Spectrum. Теперь возникает большой вопрос: В каком формате вы храните эту таблицу размером 4 ТБ history_purchase ? CSV? Как насчет паркета?
history_purchase Таблица содержит четыре столбца одинакового размера, которые хранятся в Amazon S3 в трех файлах: несжатый CSV, GZIP CSV и Parquet.
- Несжатый CSV-файл : Несжатый CSV-файл имеет общий размер 4 ТБ. Выполнение запроса для получения данных из одного столбца таблицы требует, чтобы Redshift Spectrum просканировал весь файл размером 4 ТБ. В результате этот запрос будет стоить 20 долларов.
- Файл CSV GZIP : Если вы сжимаете файл CSV с помощью GZIP, размер файла уменьшается до 1 ГБ. Отличная экономия! Однако Redshift Spectrum по-прежнему должен сканировать весь файл. Хорошая новость заключается в том, что ваш CSV-файл в четыре раза меньше, чем несжатый, поэтому вы платите четверть того, что делали раньше.Так что этот запрос будет стоить 5 долларов.
- Parquet файл : если вы сжимаете файл и конвертируете его в Apache Parquet, вы получаете 1 ТБ данных в S3. Однако, поскольку Parquet является столбцовым, Redshift Spectrum может читать только тот столбец, который имеет отношение к выполняемому запросу. Ему нужно отсканировать только четверть данных. Этот запрос будет стоить всего 1,25 доллара США.
Если вы выполняете этот запрос один раз в день в течение года, использование несжатых файлов CSV будет стоить 7300 долларов. Даже сжатые запросы CSV будут стоить более 1800 долларов.Однако при использовании формата файла Apache Parquet это будет стоить около 460 долларов. Все еще любите свой файл CSV?
Сводка
Тенденция к «бессерверным» интерактивным службам запросов и готовым пакетам обработки данных с нулевым администрированием быстро прогрессирует. Это дает командам новые возможности работать быстрее с меньшими инвестициями. Athena и Spectrum упрощают анализ данных в Amazon S3 с помощью стандартного SQL. Кроме того, Google поддерживает загрузку файлов Parquet в BigQuery и Dataproc.
Когда вы платите только за выполняемые запросы или ресурсы, такие как ЦП и хранилище, важно обратить внимание на оптимизацию данных, на которые полагаются эти системы.
Установите количество или размер файлов для запроса CTAS в Amazon Athena
Когда я запускаю запрос CREATE TABLE AS SELECT (CTAS) в Amazon Athena, я хочу определить количество файлов или объем данных для каждого файла.
Разрешение
Используйте сегментирование, чтобы задать размер файла или количество файлов в запросе CTAS.
Примечание: Следующие шаги используют набор общедоступных данных Global Historical Climatology Network Daily (s3: //noaa-ghcn-pds/csv.gz/) для иллюстрации решения. Дополнительные сведения об этом наборе данных см. В разделе Визуализация глобальных климатических данных за более чем 200 лет с помощью Amazon Athena и Amazon QuickSight. Эти шаги показывают, как изучить ваш набор данных, создать среду, а затем изменить набор данных:
- Измените количество файлов в наборе данных Amazon Simple Storage Service (Amazon S3).
- Установите приблизительный размер каждого файла.
- Преобразуйте формат данных и установите приблизительный размер файла.
Изучите набор данных
aws s3 ls s3: //noaa-ghcn-pds/csv.gz/ --summarize --recursive --human-readable Результат выглядит примерно так:
2019-11-30 01:58:05 3,3 КиБ csv.gz / 1763.csv.gz
2019-11-30 01:58:06 3.2 КиБ csv.gz / 1764.csv.gz
2019-11-30 01:58:06 3.3 КиБ csv.gz / 1765.csv.gz
2019-11-30 01:58:07 3.3 КиБ csv.gz / 1766.csv.gz
...
2019-11-30 02:05:43 199,7 МиБ csv.gz / 2016.csv.gz
2019-11-30 02:05:50 197,7 МиБ csv.gz / 2017.csv.gz
2019-11-30 02:05:54 197.0 MiB csv.gz / 2018.csv.gz
2019-11-30 02:05:57 168,8 МиБ csv.gz / 2019.csv.gz
Всего объектов: 257
Общий размер: 15,4 ГиБ Создайте среду
1. Запустите оператор, подобный следующему, чтобы создать таблицу:
СОЗДАТЬ ВНЕШНЮЮ ТАБЛИЦУ history_climate_gz (
строка идентификатора,
yearmonthday int,
строка элемента,
температура int,
m_flag строка,
q_flag строка,
s_flag строка,
obs_time int)
ФОРМАТ СТРОКИ УДАЛЕН
ПОЛЯ, ЗАКОНЧЕННЫЕ ','
СОХРАНЕНО КАК INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat '
ФОРМАТ ВЫВОДА
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
МЕСТО НАХОЖДЕНИЯ
's3: //noaa-ghcn-pds/csv.gz/' 2. Выполните следующую команду, чтобы проверить таблицу:
ВЫБРАТЬ * ИЗ Histor_climate_gz LIMIT 10 Выходные данные показывают десять строк из набора данных. После создания среды используйте один или несколько из следующих методов для изменения набора данных при выполнении запросов CTAS.
Изменить количество файлов в наборе данных
Рекомендуется сгруппировать данные по столбцу с высокой мощностью и равномерно распределенными значениями. Для получения дополнительной информации см. Разделение на сегменты и разбиение на разделы. В следующем примере мы используем поле yearmonthday .
1. Чтобы преобразовать набор данных в 20 файлов, запустите оператор, подобный следующему:
СОЗДАТЬ ТАБЛИЦУ "history_climate_gz_20_files"
С УЧАСТИЕМ (
external_location = 's3: // awsexamplebucket / Historical_climate_gz_20_files /',
format = 'ТЕКСТФАЙЛ',
bucket_count = 20,
bucketed_by = ARRAY ['yearmonthday']
) В КАЧЕСТВЕ
ВЫБРАТЬ * ИЗ Historic_climate_gz Замените следующие значения в запросе:
external_location: Расположение Amazon S3, в котором Athena сохраняет ваш запрос CTAS
Формат : формат , который требуется для вывода (например, ORC, PARQUET, AVRO, JSON или TEXTFILE)
bucket_count: количество файлов, которые вы хотите (например, 20)
bucketed_by: поле для хеширования и сохранения данных в сегменте (например, yearmonthday )
2.Выполните следующую команду, чтобы подтвердить, что корзина содержит желаемое количество файлов:
aws s3 ls s3: // awsexamplebucket /istor_climate_gz_20_files / --summarize --recursive --human-readable
Всего объектов: 20
Общий размер: 15,6 Gib Установите приблизительный размер каждого файла
1. Определите, сколько файлов вам нужно для достижения желаемого размера файла. Например, чтобы разбить набор данных 15,4 ГБ на файлы размером 2 ГБ, вам потребуется 8 файлов (15.4/2 = 7,7, округляем до 8).
2. Запустите оператор, подобный следующему:
СОЗДАТЬ ТАБЛИЦУ "history_climate_gz_2GB_files"
С УЧАСТИЕМ (
external_location = 's3: // awsexamplebucket / history_climate_gz_2GB_file /',
format = 'ТЕКСТФАЙЛ',
bucket_count = 8,
bucketed_by = ARRAY ['yearmonthday']) КАК
ВЫБРАТЬ * ИЗ Historic_climate_gz Замените следующие значения в запросе:
external_location : расположение Amazon S3, в котором Athena сохраняет ваш запрос CTAS
формат : должен быть в том же формате, что и исходные данные (например, ORC, PARQUET, AVRO, JSON или TEXTFILE )
bucket_count : количество файлов, которые вы хотите (например, 20)
bucketed_by : поле для хеширования и сохранения данных в корзине.Выберите поле с высокой мощностью.
3. Выполните следующую команду, чтобы убедиться, что набор данных содержит желаемое количество файлов:
aws s3 ls s3: // awsexamplebucket / history_climate_gz_2GB_file / --summarize --recursive --human-readable Результат выглядит примерно так:
2019-09-03 10:59:20 1,7 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00000.gz
2019-09-03 10:59:20 2,0 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00001.gz
2019-09-03 10:59:20 2,0 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00002.gz
2019-09-03 10:59:19 1,9 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00003.gz
2019-09-03 10:59:17 1,7 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00004.gz
2019-09-03 10:59:21 1,9 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00005.gz
2019-09-03 10:59:18 1,9 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00006.gz
2019-09-03 10:59:17 1,9 ГиБ history_climate_gz_2GB_file / 201_085819_00005_bzbtg_bucket-00007.gz
Всего объектов: 8
Общий размер: 15,0 Гбайт Преобразуйте формат данных и установите приблизительный размер файла
1. Запустите оператор, подобный следующему, чтобы преобразовать данные в другой формат:
СОЗДАТЬ ТАБЛИЦУ "history_climate_parquet"
С УЧАСТИЕМ (
external_location = 's3: // awsexamplebucket / Historical_climate_parquet /',
format = 'ПАРКЕТ') КАК
ВЫБРАТЬ * ИЗ Historic_climate_gz Замените в запросе следующие значения:
external_location: Расположение Amazon S3, в котором Athena сохраняет ваш запрос CTAS Формат
: формат , в который вы хотите преобразовать (ORC, PARQUET, AVRO, JSON или TEXTFILE)
2.Выполните следующую команду, чтобы подтвердить размер набора данных:
aws s3 ls s3: // awsexamplebucket / Historical_climate_parquet / --summarize --recursive --human-readable Результат выглядит примерно так:
Всего объектов: 30
Общий размер: 9,8 Гбайт 3. Определите, сколько файлов вам нужно для достижения желаемого размера файла. Например, если вам нужны файлы размером 500 МБ, а набор данных равен 9.8 ГБ, тогда вам понадобится 20 файлов (9800/500 = 19,6, округляем до 20).
4. Чтобы преобразовать набор данных в файлы размером 500 МБ, запустите оператор, подобный следующему:
СОЗДАТЬ ТАБЛИЦУ "history_climate_parquet_500mb"
С УЧАСТИЕМ (
external_location = 's3: // awsexamplebucket / Historical_climate_parquet_500mb /',
format = 'ПАРКЕТ',
bucket_count = 20,
bucketed_by = ARRAY ['yearmonthday']
) В КАЧЕСТВЕ
ВЫБРАТЬ * ИЗ исторического_климатического_парка Замените в запросе следующие значения:
external_location: Местоположение Amazon S3, в котором Athena сохраняет ваш запрос CTAS
bucket_count: количество файлов, которые вы хотите (например, 20)
bucketed_by: поле для хеширования и сохранения данные в корзине.Выберите поле с высокой мощностью.
5. Выполните следующую команду, чтобы убедиться, что набор данных содержит желаемое количество файлов:
aws s3 ls s3: // awsexamplebucket / Historical_climate_parquet_500mb / --summarize --recursive --human-readable Результат выглядит примерно так:
2019-09-03 12:01:45 333,9 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00000
2019-09-03 12:01:01 666.7 МиБ history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00001
2019-09-03 12:01:00 665.6 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00002
2019-09-03 12:01:06 666.0 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00003
2019-09-03 12:00:59 667,3 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00004
2019-09-03 12:01:27 666.0 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00005
2019-09-03 12:01:10 666.5 МиБ history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00006
2019-09-03 12:01:12 668,3 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00007
2019-09-03 12:01:03 666.8 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00008
2019-09-03 12:01:10 646,4 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00009
2019-09-03 12:01:35 639.0 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00010
2019-09-03 12:00:52 529.5 МиБ history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00011
2019-09-03 12:01:29 334,2 МиБ history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00012
2019-09-03 12:01:32 333.0 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00013
2019-09-03 12:01:34 332,2 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00014
2019-09-03 12:01:44 333,3 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00015
2019-09-03 12:01:51 333.0 МиБ history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00016
2019-09-03 12:01:39 333.0 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00017
2019-09-03 12:01:47 333.0 MiB Historical_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00018
2019-09-03 12:01:49 332,3 MiB history_climate_parquet_500mb / 201_095742_00001_uipqt_bucket-00019
Всего объектов: 20
Общий размер: 9,9 Гбайт Нужна ли вам поддержка по выставлению счетов или техническая поддержка?
Загрузка данных Parquet из облачного хранилища | BigQuery | Google Cloud
На этой странице представлен обзор загрузки данных Parquet из облачного хранилища. в BigQuery.
Паркет — это формат данных с открытым исходным кодом, ориентированный на столбцы, который широко используется в Apache Hadoop экосистема.
Когда вы загружаете данные Parquet из облачного хранилища, вы можете загрузить данные в новую таблицу или раздел, или вы можете добавить или перезаписать существующую таблицу или раздел. Когда ваши данные загружаются в BigQuery, они преобразован в столбчатый формат для Конденсатор (Формат хранения BigQuery).
Когда вы загружаете данные из облачного хранилища в таблицу BigQuery, набор данных, содержащий таблицу, должен быть в том же регионе или в нескольких региональное расположение как сегмент облачного хранилища.
Для получения информации о загрузке данных Parquet из локального файла см. Загрузка данных из локальных файлов.
Схемы паркета
Когда вы загружаете файлы Parquet в BigQuery, схема таблицы автоматически извлекается из исходных данных с самоописанием. Когда BigQuery извлекает схему из исходных данных, в алфавитном порядке используется последний файл.
Например, у вас есть следующие файлы Parquet в облачном хранилище:
gs: // mybucket / 00 / а. паркет z.паркет gs: // mybucket / 01 / б. паркет
Выполнение этой команды в программе командной строки bq загружает все файлы (как
список, разделенный запятыми), а схема получена из mybucket / 01 / b.parquet :
bq load \ --source_format = ПАРКЕТ \ таблица данных \ "gs: //mybucket/00/*.parquet", "gs: //mybucket/01/*.parquet"
При загрузке нескольких файлов Parquet с разными схемами одинаковые столбцы, указанные в нескольких схемах, должны иметь одинаковый режим в каждом определении схемы.
Когда BigQuery обнаруживает схему, некоторые типы данных Parquet преобразованы в типы данных BigQuery, чтобы сделать их совместимыми с Синтаксис BigQuery SQL. Для получения дополнительной информации см. Преобразование паркета.
Паркет компрессионный
BigQuery поддерживает следующие кодеки сжатия для блоков данных в файлах Parquet:
-
GZip -
LZO_1CиLZO_1X -
Быстрый -
ZSTD
Для загрузки данных в BigQuery необходимы разрешения IAM для запуска задания загрузки и загрузки данных в таблицы и разделы BigQuery.Если вы загружаете данные из облачного хранилища, вам также необходимы разрешения IAM для доступа к корзине, содержащей ваши данные.
Разрешения на загрузку данных в BigQuery
Для загрузки данных в новую таблицу или раздел BigQuery, а также для добавления или перезаписи существующей таблицы или раздела вам необходимы следующие разрешения IAM:
-
bigquery.tables.create -
bigquery.tables.updateData -
bigquery.tables.update -
bigquery.jobs.create
Каждая из следующих предопределенных ролей IAM включает разрешения, необходимые для загрузки данных в таблицу или раздел BigQuery:
-
роли / bigquery.dataEditor -
роли / bigquery.dataOwner -
роли / bigquery.admin(включает разрешениеbigquery.jobs.create) -
bigquery.user(включает разрешениеbigquery.jobs.create) -
bigquery.jobUser(включает разрешениеbigquery.jobs.create)
Кроме того, если у вас есть разрешение bigquery.datasets.create , вы можете создавать и
обновлять таблицы, используя задание загрузки в создаваемых наборах данных.
Для получения дополнительной информации о ролях и разрешениях IAM в BigQuery, см. Стандартные роли и разрешения.
Разрешения на загрузку данных из облачного хранилища
Для загрузки данных из корзины облачного хранилища необходимы следующие разрешения IAM:
-
склад.objects.get -
storage.objects.list(требуется, если вы используете подстановочный знак URI)
Предопределенная роль IAM роли / storage.objectViewer включает все разрешения, необходимые для загрузки данных из корзины Cloud Storage.
Загрузка данных Parquet в новую таблицу
Вы можете загрузить данные Parquet в новую таблицу, используя одно из следующих значений:
- Облачная консоль
- Команда командной строки
bqbq loadкоманда - Вакансии
.вставить метод APIи настроить задание загрузки - Клиентские библиотеки
Чтобы загрузить данные Parquet из облачного хранилища в новый BigQuery стол:
Консоль
В облачной консоли откройте страницу BigQuery.
Перейти к BigQuery
На панели Explorer разверните проект и выберите набор данных.
Разверните more_vert Действия и нажмите Открыть .
На панели сведений щелкните Создать таблицу add_box.
На странице Create table в разделе Source :
Для Создать таблицу из выберите Облачное хранилище.
В поле источника найдите или введите URI облачного хранилища. Обратите внимание, что вы не можете включать несколько URI в Облачная консоль, но подстановочные знаки поддерживается. Сегмент Cloud Storage должен находиться в том же месте. как набор данных, содержащий создаваемую вами таблицу.
Для Формат файла выберите Паркет .
На странице Создать таблицу в разделе Назначение :
Для Имя набора данных выберите соответствующий набор данных.
Убедитесь, что Тип таблицы установлен на Собственная таблица .
В поле Имя таблицы введите имя таблицы, которую вы создание в BigQuery.
В разделе Схема никаких действий не требуется. Схема самоописанный в файлах Parquet.
(Необязательно) Чтобы разделить таблицу, выберите параметры в Параметры раздела и кластера . Для получения дополнительной информации см. Создание многораздельных таблиц.
(необязательно) Для кластеризации таблица, в поле Порядок кластеризации введите от одного до четырех полей имена.
(Необязательно) Щелкните Дополнительные параметры .
- Для Предпочтение записи , оставьте Запись, если выбрано пустое значение . Этот опция создает новую таблицу и загружает в нее ваши данные.
- Для Неизвестные значения , оставьте Игнорировать неизвестные значения снятым. Эта опция применима только к файлам CSV и JSON.
- Для Encryption щелкните Управляемый клиентом ключ , чтобы использовать Ключ Cloud Key Management Service. Если вы оставите настройку для ключа, управляемого Google, , BigQuery шифрует данные в состоянии покоя.
Нажмите Создать таблицу .
После создания таблицы вы можете обновить срок ее действия, описание и метки, но вы не можете добавить срок действия раздела после таблица создается с помощью Cloud Console. Для получения дополнительной информации см. Управляющие столы.
bq
Используйте команду bq load , укажите PARQUET , используя --source_format флаг и включить URI облачного хранилища.Вы можете включить один URI, список URI, разделенных запятыми, или URI
содержащий подстановочный знак.
(Необязательно) Поставьте флаг --location и установите значение для вашего
место нахождения.
Другие дополнительные флаги включают:
-
--time_partitioning_type: включает разбиение по времени для таблицы и устанавливает тип раздела. Возможные значения:ЧАС,ДЕНЬ,МЕСЯЦиГОД. Этот флаг не является обязательным при создании таблица секционирована по столбцуDATE,DATETIMEилиTIMESTAMP.По умолчанию тип раздела для разбиения по времени —DAY. Ты не можешь изменить спецификацию разделения существующей таблицы. -
--time_partitioning_expiration: целое число, определяющее (в секундах) когда следует удалить раздел, основанный на времени. Срок годности оценивается к дате раздела в формате UTC плюс целочисленное значение. -
--time_partitioning_field: столбецDATEилиTIMESTAMP, используемый для создать многораздельную таблицу.Если временное разбиение включено без при этом значении создается многораздельная таблица во время приема. -
--require_partition_filter: если этот параметр включен, для этого параметра требуются пользователи чтобы включить предложениеWHERE, определяющее разделы для запроса. Требование разделительного фильтра может снизить стоимость и повысить производительность. Для получения дополнительной информации см. Запросы к многораздельным таблицам. -
--clustering_fields: список, разделенный запятыми, до четырех имен столбцов используется для создания кластерной таблицы. --destination_kms_key: Ключ Cloud KMS для шифрования данные таблицы.Для получения дополнительной информации о секционированных таблицах см .:
Для получения дополнительной информации о кластерных таблицах см .:
Для получения дополнительной информации о шифровании таблиц см .:
Чтобы загрузить данные Parquet в BigQuery, введите следующую команду:
bq --location = МЕСТО загрузка \ --source_format = ФОРМАТ \ НАБОР ДАННЫХ . ТАБЛИЦА \ PATH_TO_SOURCE
Заменить следующее:
-
МЕСТО: ваше местоположение. Флаг- расположениепо желанию. Например, если вы используете BigQuery в Регион Токио, вы можете установить значение флагаasia-northeast1. Вы можете установить значение по умолчанию для местоположения, используя .bigqueryrc файл. -
ФОРМАТ:ПАРКЕТ. -
DATASET: существующий набор данных. -
ТАБЛИЦА: имя таблицы, в которую вы Загрузка данных. -
PATH_TO_SOURCE: полностью квалифицированный URI облачного хранилища или список URI, разделенных запятыми. Подстановочные знаки также поддерживаются.
Примеры:
Следующая команда загружает данные из gs: //mybucket/mydata.parquet в
таблица с именем mytable в mydataset .
Бк нагрузка \
--source_format = ПАРКЕТ \
mydataset.mytable \
gs: //mybucket/mydata.parquet
Следующая команда загружает данные из gs: //mybucket/mydata.parquet в
новая секционированная таблица во время приема с именем mytable в mydataset .
Бк нагрузка \
--source_format = ПАРКЕТ \
--time_partitioning_type = ДЕНЬ \
mydataset.mytable \
gs: //mybucket/mydata.parquet
Следующая команда загружает данные из gs: //mybucket/mydata.parquet в
секционированная таблица с именем mytable в mydataset .Таблица разделена
в столбце mytimestamp .
Бк нагрузка \
--source_format = ПАРКЕТ \
--time_partitioning_field mytimestamp \
mydataset.mytable \
gs: //mybucket/mydata.parquet
Следующая команда загружает данные из нескольких файлов в gs: // mybucket / в таблицу с именем mytable в mydataset . URI облачного хранилища использует
подстановочный знак.
Бк нагрузка \
--source_format = ПАРКЕТ \
mydataset.mytable \
gs: //mybucket/mydata*.parquet
Следующая команда загружает данные из нескольких файлов в gs: // mybucket / в таблицу с именем mytable в mydataset . Команда включает запятую.
список URI облачного хранилища, разделенный символами подстановки.
Бк нагрузка \
--source_format = ПАРКЕТ \
mydataset.mytable \
"gs: //mybucket/00/*.parquet", "gs: //mybucket/01/*.parquet"
API
Создайте задание загрузки
(Необязательно) Укажите свое местоположение в расположение
свойствов разделеjobReferenceресурса job.Свойство URI источника должно быть полностью определено в формате
gs: // ВЕДРО / ОБЪЕКТ. Каждый URI может содержать один «*» подстановочный знак.Укажите формат данных Parquet, задав для свойства
sourceFormatзначениеПАРКЕТ.Чтобы проверить статус работы, позвоните
jobs.get ( JOB_ID *), заменяя JOB_ID на идентификатор задания, возвращенный исходным запрос.- Если
status.state = DONE, задание выполнено успешно. - Если присутствует свойство
status.errorResult, запрос не выполнен, и этот объект включает информацию, описывающую, что пошло не так. При сбое запроса таблица не создается и данные не загружаются. - Если
status.errorResultотсутствует, задание успешно завершено; хотя могли быть некоторые нефатальные ошибки, такие как проблемы импорт нескольких строк. В возвращенном задании перечислены нефатальные ошибки. свойство объектаstatus.errors.
- Если
Примечания API:
Задания загрузки являются атомарными и последовательными: в случае сбоя задания загрузки данные отсутствуют. доступен, и если задание загрузки выполнено успешно, доступны все данные.
Рекомендуется создать уникальный идентификатор и передать его как
jobReference.jobIdпри вызовеjobs.insertдля создания задания загрузки. Этот подход более устойчив к сбоям сети, потому что клиент может опрашивать или повторите попытку с известным идентификатором задания.Вызов
jobs.insertдля заданного идентификатора работы идемпотентен. Вы можете повторить попытку как сколько угодно раз с одним и тем же идентификатором вакансии, и не более одного из этих операции пройдут успешно.
Перейти
Перед тем, как попробовать этот образец, следуйте инструкциям по настройке Go в Краткое руководство по BigQuery с использованием клиентских библиотек.Для получения дополнительной информации см. Справочная документация по BigQuery Go API.
Java
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Java в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по BigQuery Java API.
Node.js
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Node.js в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по API BigQuery Node.js.
PHP
Перед тем, как попробовать этот пример, следуйте инструкциям по установке PHP в Краткое руководство по BigQuery с использованием клиентских библиотек.Для получения дополнительной информации см. Справочная документация по BigQuery PHP API.
Питон
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Python в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по BigQuery Python API.
Использовать Client.load_table_from_uri () для запуска задания загрузки из облачного хранилища. Чтобы использовать паркет, установите LoadJobConfig.source_format имущество в строку PARQUET и передайте конфигурацию задания как job_config аргумент метода load_table_from_uri () .Добавление или перезапись таблицы данными Parquet
Вы можете загрузить дополнительные данные в таблицу либо из исходных файлов, либо с помощью добавление результатов запроса.
В облачной консоли воспользуйтесь параметром Предпочтение записи , чтобы указать какое действие выполнять при загрузке данных из исходного файла или из запроса результат.
У вас есть следующие возможности при загрузке дополнительных данных в таблицу:
| Опция консоли | bq флажок для инструмента | Свойство BigQuery API | Описание |
|---|---|---|---|
| Запись, если пусто | Не поддерживается | WRITE_EMPTY | Записывает данные, только если таблица пуста. |
| Приложение к таблице | - заменить или - заменить = ложь ; если - [нет] заменить не указано, по умолчанию добавлено | ЗАПИСАТЬ ПРИЛОЖЕНИЕ | (по умолчанию) Добавляет данные в конец таблицы. |
| Таблица перезаписи | - заменить или - заменить = true | WRITE_TRUNCATE | Удаляет все существующие данные в таблице перед записью новых данных.Это действие также удаляет схему таблицы и удаляет все Ключ Cloud KMS. |
Если вы загружаете данные в существующую таблицу, задание загрузки может добавить данные или перезаписать таблицу.
Вы можете добавить или перезаписать таблицу одним из следующих способов:
- Облачная консоль
- Команда командной строки
bqbq loadкоманда -
jobs.insert метод APIи настройкаloadjob - Клиентские библиотеки
Для добавления или перезаписи таблицы данными Parquet:
Консоль
В облачной консоли откройте страницу BigQuery.
Перейти к BigQuery
На панели Explorer разверните проект и выберите набор данных.
Разверните more_vert Действия и нажмите Открыть .
На панели сведений щелкните Создать таблицу add_box.
На странице Create table в разделе Source :
Для Создать таблицу из выберите Облачное хранилище.
В поле источника перейдите к или введите URI облачного хранилища. Обратите внимание, что вы не можете включить несколько URI в Cloud Console, но использовать подстановочные знаки поддерживаются. Сегмент Cloud Storage должен находиться в том же месте. как набор данных, содержащий таблицу, которую вы добавляете или перезаписываете.
Для Формат файла выберите Паркет .
На странице Создать таблицу в разделе Назначение :
Для Имя набора данных выберите соответствующий набор данных.
В поле Имя таблицы введите имя таблицы, которую вы добавление или перезапись в BigQuery.
Убедитесь, что Тип таблицы установлен на Собственная таблица .
В разделе Схема никаких действий не требуется. Схема самоописанный в файлах Parquet.
Примечание: Можно изменить схему таблицы, когда вы добавляете или перезапишите его. Для получения дополнительной информации о поддерживаемых изменениях схемы во время операция загрузки, см. Изменение схем таблиц.Для Параметры раздела и кластера оставьте значения по умолчанию. Ты не может преобразовать таблицу в секционированную или кластерную таблицу путем добавления или перезаписывая его, а облачная консоль не поддерживает добавление или перезапись секционированных или кластерных таблиц в задании загрузки.
Щелкните Дополнительные параметры .
- Для Предпочтение записи выберите Добавить в таблицу или Перезаписать Стол .
- Для Неизвестные значения , оставьте Игнорировать неизвестные значения снятым. Эта опция применима только к файлам CSV и JSON.
- Для Encryption щелкните Управляемый клиентом ключ , чтобы использовать Ключ Cloud Key Management Service. Если вы оставите настройку для ключа, управляемого Google, , BigQuery шифрует данные в состоянии покоя.
Нажмите Создать таблицу .
bq
Введите команду bq load с флагом --replace , чтобы перезаписать
стол. Используйте флаг --noreplace для добавления данных в таблицу. Если нет флага
указано, по умолчанию добавляются данные. Поставьте флаг --source_format и установите его на ПАРКЕТ . Поскольку схемы Parquet извлекаются автоматически
из исходных данных с самоописанием, вам не нужно предоставлять схему
определение.
(Необязательно) Поставьте флаг --location и установите значение для вашего
место нахождения.
Другие дополнительные флаги включают:
-
--destination_kms_key: Ключ Cloud KMS для шифрования данные таблицы.
bq --location = МЕСТО загрузка \ - [нет] заменить \ --source_format = ФОРМАТ \ НАБОР ДАННЫХ . ТАБЛИЦА \ PATH_TO_SOURCE
Заменить следующее:
-
местоположение: ваше местоположение. Флаг--locationне является обязательным. Вы можете установить значение по умолчанию для местоположение с помощью .bigqueryrc файл. -
формат:ПАРКЕТ. -
набор данных: существующий набор данных. -
таблица: имя таблицы, в которую вы Загрузка данных. -
path_to_source: полностью квалифицированный URI облачного хранилища или список URI, разделенных запятыми. Подстановочные знаки также поддерживаются.
Примеры:
Следующая команда загружает данные из gs: //mybucket/mydata.parquet и
перезаписывает таблицу с именем mytable в mydataset .
Бк нагрузка \
--заменять \
--source_format = ПАРКЕТ \
mydataset.mytable \
gs: //mybucket/mydata.parquet
Следующая команда загружает данные из gs: // mybucket / mydata.паркет и
добавляет данные в таблицу с именем mytable в mydataset .
Бк нагрузка \
--noreplace \
--source_format = ПАРКЕТ \
mydataset.mytable \
gs: //mybucket/mydata.parquet
Для получения информации о добавлении и перезаписи многораздельных таблиц с помощью bq инструмент командной строки, см.
Добавление и перезапись данных многораздельной таблицы.
API
Создайте задание загрузки
(Необязательно) Укажите свое местоположение в расположение
свойствов разделеjobReferenceресурса job.Исходный URI
gs: // ВЕДРО / ОБЪЕКТ. Вы можете включить несколько URI в виде списка, разделенного запятыми. Обратите внимание, что подстановочные знаки также поддерживается.Укажите формат данных, установив Конфигурация
.load.sourceFormatвPARQUET.Укажите предпочтение записи, установив
configuration.load.writeDispositionсвойство вWRITE_TRUNCATEилиЗАПИСАТЬ ПРИЛОЖЕНИЕ.
Перейти
Перед тем, как попробовать этот образец, следуйте инструкциям по настройке Go в Краткое руководство по BigQuery с использованием клиентских библиотек.Для получения дополнительной информации см. Справочная документация по BigQuery Go API.
Java
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Java в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по BigQuery Java API.
Node.js
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Node.js в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по API BigQuery Node.js.
PHP
Перед тем, как попробовать этот пример, следуйте инструкциям по установке PHP в Краткое руководство по BigQuery с использованием клиентских библиотек.Для получения дополнительной информации см. Справочная документация по BigQuery PHP API.
Питон
Перед тем, как попробовать этот пример, следуйте инструкциям по установке Python в Краткое руководство по BigQuery с использованием клиентских библиотек. Для получения дополнительной информации см. Справочная документация по BigQuery Python API.
Чтобы заменить строки в существующей таблице, установите LoadJobConfig.write_disposition имущество в WRITE_TRUNCATE.Загрузка данных паркета, разделенного на ульи
BigQuery поддерживает загрузку разделенных на улей данных Parquet, хранящихся на Cloud Storage и заполняет столбцы секционирования улья как столбцы в целевая управляемая таблица BigQuery. Для получения дополнительной информации см. Загрузка данных с внешними секциями.
Паркет переделанный
BigQuery преобразует типы данных Parquet в следующие Типы данных BigQuery:
Преобразование типов
| Тип паркета | Логический тип паркета | Тип данных BigQuery |
|---|---|---|
Логический | Нет | БУЛЕВЫЙ |
| INT32 | Нет, ЦЕЛОЕ ( UINT_8 , UINT_16 , UINT_32 , INT_8 , INT_16 , INT_32 ) | ЦЕЛОЕ |
| INT32 | ДЕСЯТИЧНЫЙ | NUMERIC, BIGNUMERIC или STRING |
ИНТ32 | ДАТА | ДАТА |
INT64 | Нет, INTEGER ( UINT_64 , INT_64 ) | ЦЕЛОЕ |
| INT64 | ДЕСЯТИЧНЫЙ | NUMERIC, BIGNUMERIC или STRING |
INT64 | TIMESTAMP , точность = MILLIS ( TIMESTAMP_MILLIS ) | ВРЕМЯ |
INT64 | TIMESTAMP , точность = MICROS ( TIMESTAMP_MICROS ) | ВРЕМЯ |
ИНТ96 | Нет | ВРЕМЯ |
ПОПЛАВОК | Нет | ПОПЛАВОК |
ДВОЙНОЙ | Нет | ПОПЛАВОК |
BYTE_ARRAY | Нет | БАЙТОВ |
BYTE_ARRAY | СТРОКА ( UTF8 ) | СТРОКА |
| FIXED_LEN_BYTE_ARRAY | ДЕСЯТИЧНЫЙ | NUMERIC, BIGNUMERIC или STRING |
FIXED_LEN_BYTE_ARRAY | Нет | БАЙТОВ |
Вложенные группы преобразуются в STRUCT типов.Другие комбинации типов паркета и преобразованных типов не поддерживаются.
Десятичный логический тип
Decimal логических типов можно преобразовать в NUMERIC , BIGNUMERIC , или STRING типов. Преобразованный тип зависит
на параметры точности и масштаба логического типа decimal и
указанные десятичные целевые типы. Укажите десятичный целевой тип следующим образом:
Перечисление логического типа
Логические типы Enum можно преобразовать в STRING или BYTES .Укажите преобразованный целевой тип следующим образом:
Список логического типа
Вы можете включить вывод схемы для логических типов Parquet LIST . BigQuery
проверяет, находится ли узел LIST в
стандартная форма или в одной из форм, описанных правилами обратной совместимости:
// стандартная форма
<необязательный | требуется> группа <имя> (СПИСОК) {
повторяющийся список групп {
<необязательный | обязательный> элемент ;
}
}
Если да, то обрабатывается соответствующее поле для узла LIST в преобразованной схеме.
как будто узел имеет следующую схему:
повторяется <тип-элемента> <имя>
Узлы «список» и «элемент» опущены.
Преобразование имени столбца
Имя столбца должно содержать только буквы (a-z, A-Z), цифры (0-9) или подчеркивания (_), и он должен начинаться с буквы или символа подчеркивания. Максимум длина имени столбца — 300 символов. Имя столбца не может использовать ни один из следующие префиксы:
-
_ТАБЛИЦА_ -
_FILE_ -
ЧАСТЬ
Повторяющиеся имена столбцов не допускаются, даже если регистр отличается. Например,
столбец с именем Column1 считается идентичным столбцу с именем column1 .
Невозможно загрузить файлы Parquet, содержащие столбцы с точкой. (.) в имени столбца.
Если имя столбца Parquet содержит другие символы (кроме точки),
символы заменяются подчеркиванием. Вы можете добавить конечные подчеркивания к
имена столбцов, чтобы избежать коллизий. Например, если файл Parquet содержит 2
columns Column1 и column1 , столбцы загружаются как Column1 и column1_ соответственно.
Размеры паркетных полов.Стандартные размеры деревянного пола
Каковы стандартные размеры деревянного пола?
Паркетные полы бывают разных размеров по ширине, толщине и длине. У каждого производителя есть собственная линия по производству деревянных полов со своей спецификацией. Это не означает, что каждый продукт исключительно уникален, но из-за разнообразия размеров не каждый производитель предложит полный список паркетных полов во всех возможных размерах. Существуют стандарты, по которым большинство деревянных полов попадает к потребителю по типу паркетных полов.
Размеры массивного паркета
Необработанные и предварительно обработанные полы из твердой древесины обычно имеют толщину 3/4 дюйма и бывают различной ширины от 1 1/2 до 8 дюймов . Фактический слой износа полов из массивной древесины обычно составляет 5/16 « или приблизительно 8 миллиметров , что делает древесину твердых пород пригодной для многократной повторной отделки. Большая часть полов в этой категории будет иметь полосы или планки произвольной длины от 12 до 84 дюймов в зависимости от продукта.
Размеры паркетного пола
Ширина технической древесины аналогична ширине массива твердых пород, а некоторые стандартные размеры аналогичны. Большой популярностью пользуются более широкие изделия, так как у конструкционной древесины стабильность размеров намного выше по сравнению с твердым вариантом. Толщина фактического ношения обычно составляет 1/4 дюйма , но некоторые изделия могут быть намного тоньше, что затрудняет или даже делает невозможным шлифование и повторную полировку.
Плавающая древесина твердых пород обычно бывает более широких размеров — обычно 4 дюйма, или шире, и преобладают длинные куски.Многие плавающие полы имеют одинаковую длину, что позволяет придерживаться единого рисунка во время укладки. Другая уникальная характеристика, обычно используемая для плавающих полов, — это имитация нескольких узких полос на одной широкой доске.
В чем разница между планками и досками паркетного пола?
Полосы обычно относятся к продуктам для пола из твердых пород дерева с шириной 2 1/4 дюйма или более узкой и толщиной от 3/8 дюйма до 3/4 дюйма .Доски для паркета — это все, что шире 2 1/4 « в ширину при аналогичной толщине.
Каковы размеры деревянных полов, изготовленных на заказ?
Древесина лиственных пород, изготовленная на заказ, не имеет стандартных спецификаций. Некоторые изделия могут иметь толщину 1 дюйм, и длину до 12 футов или даже больше; некоторые могут иметь толщину 3/8 дюйма и длину 12 дюймов . При индивидуальном заказе все зависит от дизайна.
Размеры паркета
Обычно паркетный пол бывает квадратной формы 12 x 12 дюймов обычно 3/4 « или 5/16″ толщиной, но паркетные полы также доступны меньшего или большего размера 16 «x 16» , 18 » x 18 ” или других размеров.Некоторые нестандартные паркетные изделия могут иметь размер 2 ’x 2’ , 3 ’x 3’ или даже больше.
Обзор некоторых стандартных размеров полов из твердых пород древесины
Таблица размеров полов из твердых пород древесины
Тип этажа | Ширина | Толщина | Длина | Типичные размеры (ширина x толщина) |
Цельный | 2 1/4 дюйма | 3/8 дюйма | Обычная случайная длина | 2 1/4 дюйма x 3/4 дюйма |
3 « | 1/2 « | 3 1/4 дюйма x 3/4 дюйма | ||
3 1/4 дюйма | 5/8 « | 2 1/4 «x 1/2» | ||
4 « | 3/4 дюйма | 4 дюйма x 3/4 дюйма | ||
4 1/4 дюйма | ||||
4 3/4 дюйма | ||||
5 дюймов | ||||
6 дюймов | ||||
Инженерное дело (гвоздь) | Характеристики аналогичны массиву твердых пород дерева, но типичны толщины 1/2 дюйма и 5/8 дюйма. | |||
Инженерное дело (плавающее) | 3–12 дюймов | 3/8 дюйма | Доски ровных размеров | 3/8 дюйма x 36 дюймов |
1/2 « | 36 дюймов | 1/2 «x 48» | ||
5/8 « | 48 дюймов | 1/2 «x 60» | ||
72 « | 5/8 «x 60» | |||
В таблице указаны наиболее распространенные размеры по ширине, толщине и длине паркета.Существуют сотни других комбинаций размеров напольных покрытий, которые производители могут производить для своей продукции, и в поисках определенного размера проверьте конкретные спецификации продукта.
Насколько быстро читается файл Parquet (со стрелкой) по сравнению с CSV с помощью Pandas? | by Tirthajyoti Sarkar
Потому что вы можете захотеть читать большие файлы данных в 50 раз быстрее, чем то, что вы можете сделать с помощью встроенных функций Pandas!
Значения, разделенные запятыми (CSV), — это формат плоских файлов, широко используемый в аналитике данных.С ним просто работать, и он неплохо работает в режимах малых и средних данных. Однако, поскольку вы обрабатываете данные с большими файлами (а также, возможно, платите за их облачное хранилище), есть несколько отличных причин для перехода к форматам файлов с использованием принципа хранения данных по столбцам .
Паркет Apache — один из самых популярных из этих типов. В статье ниже обсуждаются некоторые из этих преимуществ (в отличие от использования традиционных строковых форматов, например, плоского файла CSV).
Короче говоря,
- Будучи ориентированным на столбцы, Parquet переносит в таблицу все эффективные характеристики хранения (например, блоки, группы строк, фрагменты столбцов).
- Apache Parquet создается с нуля с использованием алгоритма измельчения и сборки Google.
- Файлы Parquet были разработаны с учетом сложных вложенных структур данных.
- Apache Parquet поддерживает очень эффективные схемы сжатия и кодирования. Файл parquet можно сжать с помощью различных умных методов, таких как: (а) кодирование по словарю, (б) битовая упаковка, (в) кодирование длин серий.
Файлы Parquet — отличный выбор в ситуации, когда вам нужно хранить и читать большие файлы данных с диска или облачного хранилища. Все мы широко используем Pandas для анализа данных с помощью Python. В этой статье мы покажем, что с использованием файлов Parquet с Apache Arrow дает впечатляющее преимущество в скорости по сравнению с использованием файлов CSV с Pandas при чтении содержимого больших файлов. В частности, мы поговорим о влиянии,
- размер файла
- количество читаемых столбцов
- разреженность файла (отсутствующие значения)
PyArrow — это привязка Python (API) для Apache Рамка стрелки.Согласно их веб-сайту: « Apache Arrow — это платформа разработки для аналитики в памяти . Он содержит набор технологий, которые позволяют системам больших данных быстро обрабатывать и перемещать данные. Он определяет стандартизованный формат столбчатой памяти , не зависящий от языка, для плоских и иерархических данных, организованных для эффективных аналитических операций на современном оборудовании ».
Эти функции делают Apache arrow одной из самых быстрорастущих платформ для распределенной аналитики данных в памяти.Кроме того, он оказался идеальным транспортным уровнем в памяти для чтения или записи данных с помощью файлов Parquet.
Использование PyArrow с файлами Parquet может дать впечатляющее преимущество в скорости с точки зрения скорости чтения больших файлов данных, а после чтения объект в памяти может быть легко преобразован в обычный DataFrame Pandas.
Чтобы узнать больше обо всех функциях PyArrow, обратитесь к документации Apache.
Код для этой статьи — здесь, в моем репозитории Github .
Файлы CSV и Parquet различных размеров
Сначала мы создаем различные файлы CSV, заполненные случайно сгенерированными числами с плавающей запятой. Мы также конвертируем их в заархивированные (сжатые) файлы паркета. Все файлы имеют 100 столбцов, но разное количество строк, чтобы предоставить им файлы разного размера.
Каталог может выглядеть после этого процесса.
Использование PyArrow с файлами Parquet может дать впечатляющее преимущество в скорости с точки зрения скорости чтения больших файлов данных