Отличие бита от байта – Чем отличается бит от байта
Байты и биты – чем отличаются, что измеряют [+ВИДЕО]
В этой статье расскажу Вам про такие единицы измерения компьютерной информации как Байты и Биты — меня часто спрашивали читатели про эту сладкую парочку в комментариях.
Как известно, каждый компьютер или любой другой гаджет работает с огромным количеством информации. И для определения её объёмов были созданы специальные измерительные единицы. Каждый среднестатистический пользователь ПК наверняка знает о том, что существуют такие термины, как биты и байты.
Для того, чтобы научиться максимально быстро преобразовывать байты в гигабайты, а гигабайты в терабайты, необходимо изначально изучить особенности минимальных единиц измерения.
Работа с данными
Информация — это всё то, что мы можем видеть, слышать, или же читать. При этом, объёмы этой самой информации постоянно растут и хранить, а также систематизировать её становится всё сложнее. Сам же компьютер обрабатывает информационные блоки с помощью устройств, расположенных внутри системного блока. Между тем или иным узлом информация передаётся за счёт наличия кабелей.
Даже с помощью таких внешних устройств, как клавиатура или мышка, Вы всё равно вносите дополнительную информацию в свой компьютер, которую необходимо будет обрабатывать и в дальнейшем хранить. В быту данные, важные для нас, хранятся в записной книжке, блокноте или ежедневнике.
С компьютером всё обстоит иначе. Он вынужден фиксировать любую информацию и для хранения использует специальные носители, включая жёсткий диск. Несмотря на его компактные размеры, на самом деле в устройстве может храниться невероятное количество данных, включая миллионы документов, тысячи аудиозаписей и видеороликов.
При этом, воспринимать информацию компьютер способен не так, как наш мозг, а в кодовом эквиваленте «0» или «1». На этом и базируется двоичная система, в которой участвуют всего две цифры. Именно одна из них называется битом, который является самым маленьким носителем компьютерной информации. При этом, само устройство может как хранить биты, так и передавать их.

Читайте также на сайте:
…
…
Что такое байт
Наверняка каждый из нас слышал про азбуку Морзе, которая до сих пор активно используется в некоторых сферах деятельности. В её основе положено использование двух типов сигналов: точек и тире. Их комбинации можно расшифровать в буквы, слова и целые предложения.
Что же касается компьютерной системы шифра, то она состоит из 8 цифр, ведь из них можно получить сразу 256 комбинаций, чего хватит для кодирования цифр и букв нескольких алфавитов. Именно эти восемь цифр называют байтами.
Другими словами, в одном байте содержится 8 бит. Эту информацию нет необходимости знать в обязательном порядке, однако её понимание позволит досконально оценить размеры информации на том или ином носителе.
Подробнее узнать о трансформации привычных нам знаков в двоичный код можно с помощью калькулятора, который является базовой программой операционной системы Виндоус. Вам нужно будет лишь запустить его и перейти в режим «Программист».
После этого Вы сможете ввести любое число и нажать на кнопку «Bin». В результате отобразится кодовый шифр для указанного числа. К примеру, для 100 это будет «1100100».
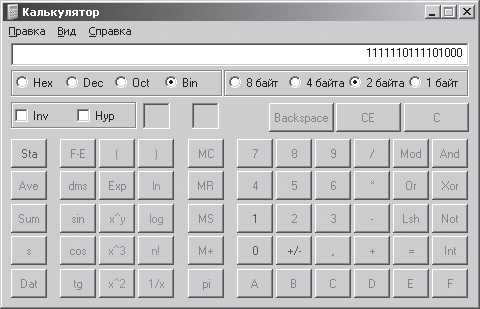
Чтобы понять, каким двоичным кодом отображаются буквы и слова, можно воспользоваться таблицей символов, которая также присутствует в каждой операционной системе Windows. Для этого вам нужно будет зайти в меню Пуск, после чего открыть стандартные программы и перейти в раздел «Служебные».
Там выберете символьную таблицу. Перед Вами откроется окно с различными знаками. При этом, Вы также можете выбрать стиль набора. Далее выделите один символ, и увидите его код в служебной строке…
…
Производные от битов бит и байтов
Как уже было сказано выше, в настоящий момент компьютеры обрабатывают невероятное количество информации, соответственно, использовать многомиллионные обозначения байтов не очень удобно. Именно поэтому, как и в математике, применяются различные приставки, значение которых известно многим со школьного курса. Хотя, в компьютерной системе есть свои особенности. В частности, 1 килобайт, это не 1000, а 1 024 байта.
Схема преобразований выглядит следующим образом:
- 1 килобайт – 1 024 байта.
- 1 мегабайт – 1 048 576 байтов.
- 1 гигабайт – 1 073 741 842 байта.
- 1 терабайт – 1 099 511 627 776 байтов.
Воспользовавшись этой таблицей Вы с лёгкостью сможете пересчитывать объёмы информации, хранящиеся на том или ином устройстве. Для наглядности, можно привести пример: один печатный лист формата А4 – это в среднем 100 килобайт, 1 фильм среднего качества – 1.5 гигабайта, фото среднего качества – 2 мегабайта.
Теперь Вы знаете, чем отличаются, а также, что измеряют Байты и Биты. До новых полезных компьютерных программ и интересных приложений для Андроид.
ПОЛЕЗНОЕ ВИДЕО
…
Самые популярные статьи за сутки:Рекомендую ещё посмотреть обзоры…
Я только обозреваю программы! Любые претензии — к их производителям!
Ссылки в комментариях публикуются после модерации.
^Наверх^
optimakomp.ru
Разница между битами и байтами | Разница Между
Ключевая разница: Бит — это наименьшая единица данных в компьютере, тогда как байт — это единица данных, состоящая из восьми битов, которые расположены последовательно.
Бит — это самая маленькая единица данных в компьютере, это одна двоичная цифра; это означает, что цифра может иметь одно из двух значений, а два значения равны 0 и 1. Биты используются для кодирования одной единицы цифровой информации. Компьютеры работают на этой базе 2 системы счисления. Компьютер использует биты, так как биты могут быть легко реализованы с помощью современных электронных технологий. Бит в основном короткое имя для двоичной цифры.

(1*2^3) + (0*2^2) + (1*2^1) + (0*2^0) = 8 + 0 + 2=10
Таким образом, 1010 как двоичное число представляет значение 10. И число битов в этом двоичном числе равно четырем. Бит может быть сохранен цифровым устройством или любой другой физической системой, но он должен удовлетворять условию существования в одном из двух возможных различных состояний
Согласно Википедии, термин байт был придуман Вернером Буххольцем в июле 1956 года, на ранней стадии проектирования компьютера IBM Stretch.
, Байт — это набор из восьми битов. Восемь битов могут быть в любом порядке, например — это может быть 00000000 или 11111111 или 01110110 или любое другое возможное упорядочение 0 и 1. Поэтому байт может представлять значения в диапазоне от 0 до 255. Эти байты используются для представления букв алфавита. и другие персонажи. Это назначение является частью стандарта для преобразования текста в двоичный файл, известный как ASCII (или код ASCII). Это означает, что каждая буква, которая читается на экране компьютера, состоит из одного байта или восьми битов. Байт также называется октетом.Соотношение между битами и байтами довольно очевидно, поскольку байт представляет собой набор из восьми битов. Таким образом, байты не существовали бы без битов.
ru.natapa.org
Разница между битами и байтами
Главное отличие — биты и байты
Биты а такжебайтов единицы памяти компьютера. главное отличие между битами и байтами является то, что бит этонаименьшее блок памяти компьютера, который имеет способность хранить максимум два разных значения тогда как байт, состоящий из 8 бит, может содержать 256 различных значений.
Что немного
Компьютеры являются электронными устройствами, и они работают только с дискретными значениями. Итак, в конце концов, любой тип данных, которые компьютер хочет обработать, преобразуется в числа. Однако компьютеры не представлять числа так же, как мы, люди. Для представления чисел мы используем десятичный система, которая использует 10 цифр (0, 1, 2, 3, 4, 5, 6, 7, 8, 9). Для представления чисел современные компьютеры используютбинарная система состоит из двух цифр (0 и 1). «Немного»
это имя, данное наименьшей единице данных, которая может быть представлена в этой системе (Немного обозначает «двоичная цифра»). то есть с точки зрения двоичных чисел,немного состоит из 0 или 1. В электронике, составляющей компьютер, бит может быть представлен двумя напряжениями. Состояние «выключено» (0 вольт) может представлять двоичный 0, а состояние «включено» (имеющее некоторое максимальное напряжение) может представлять двоичный 1.В двоичной системе любое число может быть представлено с использованием 0 и 1, хотя для двоичного кода требуется больше цифр, чтобы представить число, чем десятичное (например, десятичное число 123 представляется в двоичном виде как 1111011). Чтобы выразить сложные данные, необходимы большие числа и, следовательно, больше битов. Например, цвет может быть описан тем, сколько красного, зеленого и синего цветов входит в состав этого цвета. В используемой нами системе каждое значение для красного, зеленого или синего может принимать до 256 значений (0-255). Используя двоичный код, для представления каждого красного, синего или зеленого значения требуется 8 бит (потому что
ru.strephonsays.com
Чем отличается бит от байта — Чем Биты от Байтов отличаются? — 2 ответа
чем отличается байт от бита
Автор Галчонок задал вопрос в разделе Интернет
Чем Биты от Байтов отличаются? и получил лучший ответ
Ответ от Отряд_не_заметил_потери_бойца[гуру]
Традиционно скорость соединения измеряют в кило/мегабитах в секунду
Размер файлов — в кило/мегабайтах.
Обьем
1 байт = 8 бит;
1 Кбайт = 1024 байт.
1 Мбайт = 1024 Кбайт
и так делее.
Скорость передачи данных
1 Кбит/с = 128 байт/с
1 Мбит/с = 1024 Кбит/с = 128 кБайт/с
и так далее
Привет! Вот подборка тем с ответами на Ваш вопрос: Чем Биты от Байтов отличаются?
Ответ от Ванюха[гуру]
1 байт = 8 бит
Ответ от Вика[гуру]
восьмеркой
Ответ от Ёергей Коноплёв[мастер]
В одном Байте 8 Битов
Ответ от Злой Гений[гуру]
1 байт = 8 бит, а вот почему используются две еденицы измерения обьясню, 1 байт это символ, буква цифра знак припинания и т. д. поэтому объем документа программы измеряется в байтах (сколько в ней символов) но информация передается не символами а битами 1 и 0, и для кодировки символа используется 8 знаков, то есть для того чтоб написать слово мама надо 4 байта, но для записи информации понадобиться 32 бита и будет выглядетьчто-то вроде 110001110100110100101001010…
Ответ от Александр рура[гуру]
все это ед. инфы один байт=8 бит
Ответ от Анатолий[гуру]
размером
Ответ от Ёаша N[гуру]
размером
Ответ от -=yarik=-[новичек]
меньше чем бит нету…. а байт, ето набор из 8 битов!))
Ответ от Александр Южаков[гуру]
8 Бит = 1 Байт.
40 Бит = 5 Байт.
Это как если 1бит-это буква, а 8бит=1байт-это уже слово.
Ответ от Дмитрий[гуру]
Бит — это один звук «Туц»
Байт — это 8 звуков «туц-туц-туц-туц ХОП туц-туц-туц-туц»
Ответ от Xepb[гуру]
ты про то что скорость соединения измеряется в kbps а обьем данных в Kb 77
Ответ от Ёергей RAZE[мастер]
Вот тут не только биты и байты, есть че покруче) )
Ответ от UROBOROS[гуру]
битами людей бьют, а байтам вроде бы как то не ударишь что ли))
Ответ от 2 ответа[гуру]
Привет! Вот еще темы с похожими вопросами:
Байт на Википедии
Посмотрите статью на википедии про Байт
2oa.ru
О битах, байтах и скорости интернет соединения
92935 08.08.2009Поделиться
Класснуть
Поделиться
Твитнуть
Плюсануть
Для начала попробуем разобраться, что же такое биты и байты. Бит это самая наименьшая единица измерения количества информации. Наравне с битом активно используется байт. Байт равен 8 бит. Попробуем изобразить это наглядно на следующей диаграмме.
Думаю, с этим все понятно и не имеет смысла останавливаться подробнее. Так как бит и байт это очень маленькие величины, то в основном они используются с приставками кило, мега и гига. Наверняка вы слышали о них еще со школьной программы. Общепринятые единицы и их сокращения мы соединили в таблицу.
| Название | Аббревиатура английская | Аббревиатура русская | Значение |
|---|---|---|---|
| бит | bit (b) | б | 0 или 1 |
| байт | Byte (B) | Б | 8 бит |
| килобит | kbit (kb) | кбит (кб) | 1000 бит |
| килобайт | KByte (KB) | КБайт (KБ) | 1024 байта |
| мегабит | mbit (mb) | мбит (мб) | 1000 килобит |
| мегабайт | MByte (MB) | МБайт (МБ) | 1024 килобайта |
| гигабит | gbit (gb) | гбит (гб) | 1000 мегабит |
| гигабайт | GByte (GB) | ГБайт (ГБ) | 1024 мегабайта |
Теперь попробуем определиться с величинами измерения скорости интернет соединения.
Говоря понятным языком, скорость подключения это количество получаемой или отправляемой вашим компьютером информации в единицу времени. В качестве единицы времени в данном случае принято считать секунду а в качестве количества информации кило или мегабит.
Таким образом, если ваша скорость 128 Kbps это означает, что ваше соединение имеет пропускную способность 128 килобит в секунду или же 16 килобайт в секунду.
Много это или мало судить вам. Для того чтобы более материально почувствовать вашу скорость рекомендую воспользоваться нашими тестами. Определить время, необходимое для закачки файла, определенного вами размера, при вашей скорости подключения. Также вы можете посмотреть, файл какого объема вы сможете скачать за определенный вами период времени при вашей скорости подключения.
Используя наши тесты необходимо помнить и учитывать, что наш сервер, на котором собственно и расположены все эти тесты находится от вашего компьютера достаточно далеко и соответственно на результатах может сказываться как загруженность нашего сервера (на нашем сайте в часы пик одновременно производят замер скорости соединения более 1000 человек), так и загруженность интернет линий.
Если бы наш сервер стоял за одним столом с вашим компьютером и они были бы подключены друг к другу одним проводом, тогда можно было бы вести речь о наиболее точных результатах. В нашем же случае, как показывает практика, подключение вашего компьютера к нашему серверу для тестирования происходит в среднем через 10 других серверов.
Поделиться
Класснуть
Поделиться
Твитнуть
Плюсануть
Please enable JavaScript to view the comments powered by Disqus.2ip.ru
Разбираемся с прямым и обратным порядком байтов / Habr
Перевод статьи Халида Азада — Understanding Big and Little Endian Byte OrderПроблемы с порядком байтов очень расстраивают, и я хочу избавить Вас от горя, которое довелось испытать мне. Вот ключевые тезы:
- Проблема: Компьютеры, как и люди, говорят на разных языках. Одни записывают данные “слева направо” другие “справа налево”. При этом каждое устройство отлично считывает собственные данные — проблемы начинаются, когда один компьютер сохраняет данные, а другой пытается эти данные считать.
- Решение: Принять некий общий формат (например, весь сетевой трафик передается в едином формате). Или всегда добавлять заголовок, описывающий формат хранения данных. Если считанный заголовок имеет обратный порядок, значит данные сохранены в другом формате и должны быть переконвертированы.
Числа и данные
Наиболее важная концепция заключается в понимании разницы между числами и данными, которые эти числа представляют. Число — это абстрактное понятия, как исчислитель чего-то. У Вас есть десять пальцев. Понятие “десять” не меняется, в зависимости от использованного представления: десять, 10, diez (испанский), ju (японский), 1010 (бинарное представление), Х (римские числа)… Все эти представления указывают на понятие “десяти”.
Сравним это с данными. Данные — это физическое понятие, просто последовательность битов и байтов, хранящихся на компьютере. Данные не имеют неотъемлемого значения и должны быть интерпретированы тем, кто их считывает.
Данные — это как человеческое письмо, просто набор отметок на бумаге. Этим отметкам не присуще какое-либо значение. Если мы видим линию и круг (например, |O), то можно интерпретировать это как “десять”. Но это лишь предположение, что считанные символы представляют число. Это могут быть буквы “IO” — название спутника Юпитера. Или, возможно, имя греческой богини. Или аббревиатура для ввода/вывода. Или чьи-то инициалы. Или число 2 в бинарном представлении (“10”). Этот список предположений можно продолжить. Дело в том, что один фрагмент данных (|O) может быть интерпретировано по разному, и смысл остается не ясен, пока кто-то не уточнит намерения автора.
Компьютеры сталкиваются с такой же проблемой. Они хранят данные, а не абстрактные понятия, используя при этом 1 и 0. Позднее они считывают эти 1 и 0 и пытаются воссоздать абстрактные понятия из набора данных. В зависимости от сделанных допущений, эти 1 и 0 могут иметь абсолютно разное значение.
Почему так происходит? Ну, вообще-то нет такого правила, что компьютеры должны использовать один и тот же язык, так же, как нет такого правила и для людей. Каждый компьютер одного типа имеет внутреннюю совместимость (он может считывать свои собственные данные), но нет никакой гарантии, как именно интерпретирует эти данные компьютер другого типа.
Основные концепции:
- Данные (биты и байты или отметки на бумаге) сами по себе не имеют смысла. Они должны быть интерпретированы в какое-то абстрактное понятие, например, число.
- Как и люди, компьютеры имеют различные способы хранения одного и того же абстрактного понятия (например, мы можем различными способами сказать “10”).
Храним числа как данные
К счастью, большинство компьютеров хранят данные всего в нескольких форматах (хотя так было не всегда). Это дает нам общую отправную точку, что делает жизнь немного проще:
- Бит имеет два состояния (включен или выключен, 1 или 0).
- Байт — это последовательность из 8 бит. Крайний левый бит в байте является старшим. То есть двоичная последовательность 00001001 является десятичным числом девять. 00001001 = (2^3 + 2^0 = 8 + 1 = 9).
- Биты нумеруются справа налево. Бит 0 является крайним правым и он наименьший. Бит 7 является крайним левым и он наибольший.
Мы можем использовать эти соглашения в качестве строительного блока для обмена данными. Если мы сохраняем и читаем данные по одному байту за раз, то этот подход будет работать на любом компьютере. Концепция байта одинаковая на всех машинах, понятие “байт 0” одинакова на всех машинах. Компьютеры также отлично понимают порядок, в котором Вы посылаете им байты — они понимают какой байт был прислан первым, вторым, третьим и т. д. “Байт 35” будет одним и тем же на всех машинах.
Так в чем же проблема — компьютеры отлично ладят с одиночными байтами, правда? Ну, все превосходно для однобайтных данных, таких как ASCII-символы. Однако, много данных используют для хранения несколько байтов, например, целые числа или числа с плавающей точкой. И нет никакого соглашения о том, в каком порядке должны хранится эти последовательности.
Пример с байтом
Рассмотрим последовательность из 4 байт. Назовем их W X Y и Z. Я избегаю наименований A B C D, потому что это шестнадцатеричные числа, что может немного запутывать. Итак, каждый байт имеет значение и состоит из 8 бит.
Имя байта W X Y Z
Позиция 0 1 2 3
Значение (hex) 0x12 0x34 0x56 0x78
Например, W — это один байт со значением 0х12 в шестнадцатеричном виде или 00010010 в бинарном. Если W будет интерпретироваться как число, то это будет “18” в десятеричной системе (между прочим, ничто не указывает на то, что мы должны интерпретировать этот байт как число — это может быть ASCII-символ или что-то совсем иное). Вы все еще со мной? Мы имеем 4 байта, W X Y и Z, каждый с различным значением.
Понимаем указатели
Указатели являются ключевой частью программирования, особенно в языке С. Указатель представляет собой число, являющееся адресом в памяти. И это зависит только от нас (программистов), как интерпретировать данные по этому адресу.
В языке С, когда вы кастите (приводите) указатель к конкретному типу (такому как char * или int *), это говорит компьютеру, как именно интерпретировать данные по этому адресу. Например, давайте объявим:
void *p = 0; // p указатель на неизвестный тип данных
// p нулевой указатель - не разыменовывать
char *c; // c указатель на один байт
Обратите внимание, что мы не можем получить из р данные, потому что мы не знаем их тип. р может указывать на цифру, букву, начало строки, Ваш гороскоп или изображение — мы просто не знаем, сколько байт нам нужно считать и как их интерпретировать.
Теперь предположим, что мы напишем:
c = (char *)p;
Этот оператор говорит компьютеру, что р указывает на то же место, и данные по этому адресу нужно интерпретировать как один символ (1 байт). В этом случае, с будет указывать на память по адресу 0, или на байт W. Если мы выведем с, то получим значение, хранящееся в W, которое равно шестнадцатеричному 0x12 (помните, что W — это полный байт). Этот пример не зависит от типа компьютера — опять же, все компьютеры одинаково хорошо понимают, что же такое один байт (в прошлом это было не всегда так).
Этот пример полезен, он одинаково работает на все компьютерах — если у нас есть указатель на байт (char *, один байт), мы можем проходить по памяти, считывая по одному байту за раз. Мы можем обратиться к любому месту в памяти, и порядок хранения байт не будет иметь никакого значения — любой компьютер вернет нам одинаковую информацию.
Так в чем же проблема?
Проблемы начинаются, когда компьютер пытается считать несколько байт. Многие типы данных состоят больше чем из одного байта, например, длинные целые (long integers) или числа с плавающей точкой. Байт имеет только 256 значений и может хранить числа от 0 до 255.
Теперь начинаются проблемы — если Вы читаете многобайтные данные, то где находится старший байт?
- Машины с порядком хранения от старшего к младшему (прямой порядок) хранят старший байт первым. Если посмотреть на набор байтов, то первый байт (младший адрес) считается старшим.
- Машины с порядком хранения от младшего к старшему (обратный порядок) хранят младший байт первым. Если посмотреть на набор байт, то первый байт будет наименьшим.
Такое именование имеет смысл, правда? Тип хранения от старшего к младшему подразумевает, что запись начинается со старшего и заканчивается младшим (Между прочим, английский вариант названий от старшего к младшего (Big-endian) и от младшего к старшему (Little-endian) взяты из книги “Путешествия Гулливера”, где лилипуты спорили о том, следует ли разбивать яйцо на маленьком конце (little-end) или на большом (big-end)). Иногда дебаты компьютеров такие же осмысленные 🙂
Повторюсь, порядок следования байтов не имеет значения пока Вы работаете с одним байтом. Если у Вас есть один байт, то это просто данные, которые Вы считываете и есть только один вариант их интерпретации (опять таки, потому что между компьютерами согласовано понятие одного байта).
Теперь предположим, что у нас есть 4 байта (WXYZ), которые хранятся одинаково на машинах с обоими типами порядка записи байтов. То есть, ячейка памяти 0 соответствует W, ячейка 1 соответствует X и т. д.
Мы можем создать такое соглашение, помня, что понятие “байт” является машинно-независимым. Мы можем обойти память по одному байту за раз и установить необходимые значения. Это будет работать на любой машине.
c = 0; // указывает на позицию 0 (не будет работать на реальной машине!)
*c = 0x12; // устанавливаем значение W
c = 1; // указывает на позицию 1
*c = 0x34; // устанавливаем значение X
... // то же повторяем для Y и Z
Такой код будет работать на любой машине и успешно установит значение байт W, X, Y и Z расположенных на соответствующих позициях 0, 1, 2 и 3.
Интерпретация данных
Теперь давайте рассмотрим пример с многобайтными данными (наконец-то!). Короткая сводка: “short int” это 2-х байтовое число (16 бит), которое может иметь значение от 0 до 65535 (если оно беззнаковое). Давайте используем его в примере.
short *s; // указатель на short int (2 байта)
s = 0; // указатель на позицию 0; *s это значение
Итак, s это указатель на short int, и сейчас он указывает на позицию 0 (в которой хранится W). Что произойдет, когда мы считаем значение по указателю s?
- Машина с прямым порядком хранения: Я думаю, short int состоит из двух байт, а значит я считаю их. Позиция s это адрес 0 (W или 0х12), а позиция s + 1 это адрес 1 (X или 0х34). Поскольку первый байт является старшим, то число должно быть следующим 256 * байт 0 + байт 1 или 256 * W + X, или же 0х1234. Я умножаю первый байт на 256 (2^8) потому что его нужно сдвинуть на 8 бит.
- Машина с обратным порядком хранения: Я не знаю что курит мистер “От старшего к младшему”. Я соглашусь, что short int состоит из 2 байт и я считаю их точно также: позиция s со значение 0х12 и позиция s + 1 со значением 0х34. Но в моем мире первым является младший байт! И число должно быть байт 0 + 256 * байт 1 или 256 * X + W, или 0х3412.
Обратите внимание, что обе машины начинали с позиции s и читали память последовательно. Не никакой путаницы в том, что значит позиция 0 и позиция 1. Как и нет никакой путаницы в том, что являет собой тип short int.
Теперь Вы видите проблему? Машина с порядком хранения от старшего к младшему считает, что s = 0x1234, в то время как машина с порядком хранения от младшего к старшему думает, что s = 0x3412. Абсолютно одинаковые данные дают в результате два совершенно разных числа.
И еще один пример
Давайте для “веселья” рассмотрим еще один пример с 4 байтовым целым:
int *i; // указатель на int (4 байты 32-битовой машине)
i = 0; // указывает на позицию 0, а *i значение по этому адресу
И опять мы задаемся вопросом: какое значение хранится по адресу i?
- Машина с прямым порядком хранения: тип int состоит из 4 байт и первый байт является старшим. Считываю 4 байта (WXYZ) из которых старший W. Полученное число: 0х12345678.
- Машина с обратным порядком хранения: несомненно, int состоит из 4 байт, но старшим является последний. Так же считываю 4 байта (WXYZ), но W будет расположен в конце — так как он является младшим. Полученное число: 0х78563412.
Одинаковые данные, но разный результат — это не очень приятная вещь.
Проблема NUXI
Проблему с порядком байт иногда называют проблемой NUXI: слово UNIX, сохраненное на машинах с порядком хранения от старшего к младшему, будет отображаться как NUXI на машинах с порядком от младшего к старшему.
Допустим, что мы собираемся сохранить 4 байта (U, N, I, и X), как два short int: UN и IX. Каждая буква занимает целый байт, как в случае с WXYZ. Для сохранения двух значений типа short int напишем следующий код:
short *s; // указатель для установки значения переменной типа short
s = 0; // указатель на позицию 0
*s = UN; // устанавливаем первое значение: U * 256 + N (вымышленный код)
s = 2; // указатель на следующую позицию
*s = IX; // устанавливаем второе значение: I * 256 + X
Этот код не является специфичным для какой-то машины. Если мы сохраним значение “UN” на любой машине и считаем его обратно, то обратно получим тоже “UN”. Вопрос порядка следования байт не будет нас волновать, если мы сохраняем значение на одной машине, то должны получить это же значение при считывании.
Однако, если пройтись по памяти по одному байту за раз (используя трюк с char *), то порядок байт может различаться. На машине с прямым порядком хранения мы увидим:
Byte: U N I X
Location: 0 1 2 3
Что имеет смысл. “U” является старшим байтом в “UN” и соответственно хранится первым. Такая же ситуация для “IX”, где “I” — это старший байт и хранится он первым.
На машине с обратным порядком хранения мы скорее всего увидим:
Byte: N U X I
Location: 0 1 2 3
Но и это тоже имеет смысл. “N” является младшим байтом в “UN” и значит хранится он первым. Опять же, хотя байты хранятся в “обратном порядке” в памяти, машины с порядком хранения от младшего к старшему знают что это обратный порядок байт, и интерпретирует их правильно при чтении. Также, обратите внимание, что мы можем определять шестнадцатеричные числа, такие как 0x1234, на любой машине. Машина с обратным порядком хранения байтов знает, что Вы имеете в виду, когда пишите 0x1234 и не заставит Вас менять значения местами (когда шестнадцатеричное число отправляется на запись, машина понимает что к чему и меняет байты в памяти местами, скрывая это от глаз. Вот такой трюк.).
Рассмотренный нами сценарий называется проблемой “NUXI”, потому что последовательность “UNIX” интерпретируется как “NUXI” на машинах с различным порядком хранения байтов. Опять же, эта проблема возникает только при обмене данными — каждая машина имеет внутреннюю совместимость.
Обмен данными между машинами с различным порядком хранения байтов
Сейчас компьютеры соединены — прошли те времена, когда машинам приходилось беспокоиться только о чтении своих собственных данных. Машинам с различным порядком хранения байтов нужно как-то обмениваться данными и понимать друг друга. Как же они это делают?
Решение 1: Использовать общий формат
Самый простой подход состоит в согласовании с общим форматом для передачи данных по сети. Стандартным сетевым является порядок от старшего к младшему, но некоторые люди могут расстроиться, что не победил порядок от младшего к старшему, поэтому просто назовем его “сетевой порядок”.
Для конвертирования данных в соответствии с сетевым порядком хранения байтов, машины вызывают функцию hton() (host-to-network). На машинах с прямым порядком хранения эта функция не делает ничего, но мы не будем говорить здесь об этом (это может разозлить машины с обратным порядком хранения 🙂 ).
Но важно использовать функцию hton() перед отсылкой данных даже если Вы работаете на машине с порядком хранения от старшего к младшему. Ваша программа может стать весьма популярной и будет скомпилирована на различных машинах, а Вы ведь стремитесь к переносимости своего кода (разве не так?).
Точно также существует функция ntoh() (network-to-host), которая используется для чтения данных из сети. Вы должны использовать ее, чтобы быть уверенными, что правильно интерпретируете сетевые данные в формат хоста. Вы должны знать тип данных, которые принимаете, чтобы расшифровать их правильно. Функции преобразования имеют следующий вид:
htons() - "Host to Network Short"
htonl() - "Host to Network Long"
ntohs() - "Network to Host Short"
ntohl() - "Network to Host Long"
Помните, что один байт — это один байт и порядок не имеет значения.
Эти функции имеют критическое значение при выполнении низкоуровневых сетевых операций, таких как проверка контрольной суммы IP-пакетов. Если Вы не понимаете сути проблемы с порядком хранения байтов, то Ваша жизнь будет наполнена болью — поверьте мне на слово. Используйте функции преобразования и знайте, зачем они нужны.
Решение 2: Использования маркера последовательности байтов (Byte Order Mark — BOM)
Этот подход подразумевает использование некого магического числа, например 0xFEFF, перед каждым куском данных. Если Вы считали магическое число и его значение 0xFEFF, значит данные в том же формате, что и у Вашей машины и все хорошо. Если Вы считали магическое число и его значение 0xFFFE, это значит, что данные были записаны в формате, отличающемся от формата вашей машины и Вы должны будете преобразовать их.
Нужно отметить несколько пунктов. Во-первых, число не совсем магическое, как известно программисты часто используют этот термин для описания произвольно выбранных чисел (BOM может быть любой последовательностью различных байтов). Такая пометка называется маркером последовательности байтов потому что показывает в каком порядке данные были сохранены.
Во-вторых, BOM добавляет накладные расходы для всех передаваемых данных. Даже в случае передачи 2 байт информации Вы должны добавлять к ним 2 байта маркера BOM. Пугающе, не так ли?
Unicode использует BOM, когда сохраняет многобайтные данные (некоторые кодировки Unicode могут иметь по 2, 3 и даже 4 байта на символ). XML позволяет избежать этой путаницы, сохраняя данные сразу в UTF-8 по умолчанию, который сохраняет информацию Unicode по одному байту за раз. Почему это так круто?
Повторяю в 56-й раз — потому что проблема порядка хранения не имеет значения для единичных байт.
Опять же, в случае использования BOM может возникнуть другие проблемы. Что, если Вы забудете добавить BOM? Будете предполагать, что данные были отправлены в том же формате, что и Ваши? Прочитаете данные и, увидев что они “перевернуты” (что бы это не значило), попытаетесь преобразовать их? Что, если правильные данные случайно будут содержать неправильный BOM? Эти ситуации не очень приятные.
Почему вообще существует эта проблема? Нельзя ли просто договориться?
Ох, какой же это философский вопрос. Каждый порядок хранения байтов имеет свои преимущества. Машины с порядком следования от младшего к старшему позволяют читать младший байт первым, не считывая при этом остальные. Таким образом можно легко проверить является число нечетным или четным (последний бит 0), что очень здорово, если Вам необходима такая проверка. Машины с порядком от старшего к младшему хранят данные в памяти в привычном для человека виде (слева направо), что упрощает низкоуровневую отладку.
Так почему же все просто не договорятся об использовании одной из систем? Почему одни компьютеры пытаются быть отличными от других? Позвольте мне ответить вопросом на вопрос: почему не все люди говорят на одном языке? Почему в некоторых языках письменность слева направо, а у других справа налево?
Иногда системы развиваются независимо, а в последствии нуждаются во взаимодействии.
Эпилог: Мысли на прощание
Вопросы с порядком хранения байтов являются примером общей проблемы кодирования — данные должны представлять собой абстрактные понятия, и позднее это понятие должно быть создано из данных. Эта тема заслуживает отдельной статьи (или серии статей), но Вы должны иметь лучшее понимание проблемы, связанной с порядком хранения байтов.
habr.com
Чем отличается бит от байта — Полезные Советы — На книги.ру
Все фотографии, текстовые документы и программы хранятся в компьютерной памяти в виде битов и байтов. Что представляют собой эти мельчайшие единицы информации и сколько бит в байте?

Хранение данных в памяти
Компьютерная память представляет собой огромный набор ячеек, наполненных нулями и единицами. Ячейка — это минимальный объем данных, к которому может обращаться считывающее устройство. Физически она представляет собой триггер (в современных компьютерах). Триггер настолько мал, что его сложно рассмотреть даже под микроскопом. У каждой ячейки есть уникальный адрес, по которому ее находит та или иная программа.
Под ячейкой в большинстве случаев понимают один байт. Но, в зависимости от разрядности архитектуры, она может объединять в себе 2, 4 или 8 байт. Байт воспринимается электронными устройствами как единое целое, но на самом деле он состоит из еще меньших ячеек — битов. В 1 байте можно закодировать какой-нибудь символ, например, букву или цифру, в то время как 1 бита для этого недостаточно.
Контроллеры редко оперируют отдельными битами, хотя технически это возможно. Вместо этого идет обращение к целым байтам или даже группам байтов.

Что такое бит?
Часто под битом понимают единицу измерения информации. Такое определение нельзя назвать точным, потому что само понятие информации достаточно размыто. Если говорить более корректно, то бит — это буква компьютерного алфавита. Слово «бит» происходит от английского выражения «binary digit», что дословно означает «двоичная цифра».
Алфавит компьютеров прост и состоит всего из двух символов: 1 и 0 (наличие или отсутствие сигнала, истина или ложь). Этого набора вполне достаточно, чтобы логически описать все, что угодно. Третье состояние, под которым понимают молчание компьютера (прекращение передачи сигналов), является мифом.
Сама по себе буква не несет в себе никакой ценности с точки зрения информации: глядя на единицу или ноль, невозможно понять даже то, к какого рода данным это значение относится. И фото, и тексты, и программы в конечном счете состоят из единиц и нулей. Поэтому бит неудобен в качестве самостоятельной единицы. Следовательно, биты необходимо объединять для того, чтобы кодировать с их помощью полезную информацию.

Что такое байт?
Если бит — это буква, то байт представляет собой подобие слова. Один байт может содержать текстовый символ, целое число, часть большого числа, два небольших числа и т. д. Таким образом, в байте уже содержится осмысленная информация, хоть и в небольшом объеме.
Начинающим программистам и просто любознательным пользователям интересно, сколько в 1 байте битов. В современных компьютерах один байт всегда равняется восьми битам.
Если бит способен принимать только два значения, то сочетание восьми битов способно создавать 256 различных комбинаций. Число 256 образуется возведением двойки в восьмую степень (в соответствии с тем, сколько битов в байте).
Один бит — это 1 или 0. Два бита уже могут создавать комбинации: 00, 01, 10 и 11. Когда дело доходит до 8 бит, то вариантов сочетания нулей и единиц в диапазоне 00000000 … 11111111 получается как раз 256. Если запомнить, сколько значений может принимать и сколько бит содержится в одном байте, то запомнить эту цифру будет очень легко.
Каждое сочетание символов может нести в себе различную информацию в зависимости от кодировки (ASCII, Юникод и др.). Именно поэтому пользователи сталкиваются с тем, что введенная на русском языке информация иногда выводится в виде замысловатых символов.

Особенности двоичной системы счисления
Двоичная система имеет все те же свойства, что и привычная нам десятичная: числа, состоящие из единиц и нулей, можно складывать, вычитать, умножать и т. д. Разница лишь в том, что система состоит не из 10-ти, а всего из 2-х цифр. Именно поэтому ее удобно использовать для шифрования информации.
В любой позиционной системе исчисления числа состоят из разрядов: единиц, десятков, сотен и т. д. В десятичной системе максимальное значение одного разряда равно 9, а в бинарной системе — 1. Так как один разряд может принимать лишь два значения, бинарные числа быстро увеличиваются в длину. Например, привычное нам число 9 будет записано как 1001. Это значит, что девятка будет записана четырьмя символами, при этом один двоичный символ будет соответствовать одному биту.
Почему информация шифруется в двоичной форме?
Десятичная система удобна для ввода и вывода информации, а двоичная — для организации процесса ее преобразования. Также очень популярны системы, которые содержат восемь и шестнадцать символов: они переводят машинные коды в удобную форму.
Двоичная система наиболее удобна с точки зрения логики. Единица условно означает «да»: есть сигнал, утверждение истинно и т. д. Ноль ассоциируется со значением «нет»: значение ложно, сигнала нет и т. д. Любой открытый вопрос можно преобразовать в один или несколько вопросов с вариантами ответов «да» или «нет». Третий вариант, например, «неизвестно», будет абсолютно бесполезным.
В ходе развития компьютерных технологий были разработаны и трехразрядные емкости для хранения информации, которые называются триты. Они могут принимать три значения: 0 — емкость пуста, 1 — емкость заполнена наполовину и 2 — полная емкость. Однако двоичная система оказалась более простой и логичной, поэтому получила значительно большую популярность.
Сколько бит в байте было раньше?
Раньше нельзя было сказать однозначно, сколько бит в байте. Первоначально под байтом понимали машинное слово, то есть то количество бит, которое компьютер может обработать за один рабочий цикл (такт). Когда ЭВМ еще не помещались в рабочих кабинетах, разные микропроцессоры работали с байтами различных размеров. Байт мог включать в себя 6 бит, а у первых моделей IBM его размер достигал 9 бит.
Сегодня 8-битные байты стали настолько привычными, что даже в определении байта часто говорится, что это единица информации, состоящая из 8 бит. Тем не менее, в ряде архитектур байт равняется 32 битам и выступает в качестве машинного слова. Такие архитектуры применяются в некоторых суперкомпьютерах и сигнальных процессорах, но не на привычных нам компьютерах, ноутбуках и мобильных телефонах.
Почему победил восьмибитный стандарт?

Байты приобрели восьмибитный размер благодаря платформе IBM PC с популярнейшим в свое время 8-битным процессором Intel 8086. Распространенность этой модели способствовала тому, что в 1970-х гг. 8 бит в байте фактически стало стандартным значением.
Восьмибитный стандарт удобен тем, что позволяет хранить в 1 байте два символа десятичной системы. При 6-битной системе возможно хранение одной цифры, в то время как 2 бита оказываются лишними. В 9 бит можно записать 2 цифры, но все равно остается один лишний бит. Число 8 является третьей степенью двойки, что обеспечивает дополнительное удобство.
Области использования битов и байтов
Многие пользователи задаются вопросом: как не перепутать бит и байт? В первую очередь необходимо обратить внимание на то, как написано обозначение: сокращенно байт пишется в виде большой буквы «Б» (на английском — «B»). Соответственно, для обозначения бита служит маленькая буква «б» («b»).
Однако всегда есть вероятность, что регистр выбран неверно (например, некоторые программы автоматически переводят весь текст в нижний или верхний регистр). В таком случае следует знать, что принято измерять в битах, а что — в байтах.

Традиционно байтами измеряют объемы: размер жесткого диска, флешки и любого другого носителя будет указан в байтах и укрупненных единицах, например, гигабайтах.
Биты служат для измерения скорости. Количество информации, которую пропускает канал, скорость Интернета и т. п. измеряются в битах и производных единицах, например, мегабитах. Скорость скачивания файлов также всегда выводится в битах.
При желании можно перевести биты в байты или наоборот. Для этого достаточно вспомнить, сколько бит в байте, и произвести простое математическое вычисление. Биты превращаются в байты путем деления на восьмерку, обратный перевод осуществляется при помощи умножения на то же самое число.
Что такое машинное слово?
novoevmire.biz